
很多人第一次听到 RAG,会觉得它像是一个很“高级”的 AI 架构:向量数据库、语义检索、Embeddings、智能体、记忆、工作流自动化,名词一个接一个,似乎不写代码就很难真正做出来。其实把它拆开以后,逻辑并不复杂。你真正要完成的事情只有两件:先把知识放进去,再在用户提问时把正确的知识取出来。
这篇教程会带你用 n8n + Supabase + OpenAI 做出一个可以运行的、适合初学者的 无代码 RAG 智能体。重点不是“照着做完一个演示”,而是让你理解这套系统的关键构成:为什么要分块、为什么要做 Embeddings、向量检索到底在检索什么、为什么记忆和 RAG 不是一回事、以及你在真正落地时最容易踩到哪些坑。
如果你读完后能自己换一份文档、换一个业务场景、换一个提问方式,但依然能把系统配置起来、测起来、调起来,那这篇文章就达到了目的。
先把概念摆正:RAG 不等于“向量数据库”
RAG 是 Retrieval-Augmented Generation,中文常说“检索增强生成”。这里最重要的不是“生成”,而是“增强”两个字。增强的意思是:模型在回答问题时,不只是依赖它原本训练时学到的通用知识,而是先去找一份与你当前问题相关的外部信息,再基于那份信息回答。
你可以把它理解成一个很朴素的过程:
- 用户先提出问题。
- 系统把这个问题转换成可用于语义匹配的数值表示。
- 系统去知识库里找语义上最接近的内容片段。
- 把这些片段作为上下文交给模型。
- 模型结合这些上下文给出回答。
所以,RAG 的核心不是“让模型凭空更聪明”,而是“让模型在回答前先查资料”。这也是为什么它特别适合以下场景:
- 企业内部知识库问答
- 客服 FAQ 助手
- 产品文档助手
- SOP 或流程手册检索
- 合规政策、制度说明、操作标准等需要依据原文回答的场景
很多新手一听到 RAG 就立刻把注意力全部放到向量数据库上,这是不完整的。向量数据库只是实现“检索”的一种方式,而且非常常见、非常有效;但 RAG 的本质是“先取证据,再生成答案”。这一点理解正确,后面配置每个节点时才不会混乱。
这套系统其实只有两部分
你要搭的不是一个单一流程,而是两段逻辑不同的工作流。
第一部分:知识入库流水线
它的职责是把文档变成以后可检索的向量数据。典型步骤是:
- 从数据源读取文档
- 把文档切成多个块
- 用 Embeddings 模型把每个块转成向量
- 把这些向量写入 Supabase 的向量存储
第二部分:RAG 问答智能体
它的职责是接收用户问题,并基于刚才写进去的知识进行回答。典型步骤是:
- 用户在聊天入口发起提问
- 系统把问题做 Embedding
- 去向量库里找最相近的内容块
- 把问题和召回的内容一起交给模型
- 模型生成回答
- 如果配置了记忆,还会把聊天内容写进短期记忆存储
你可以把这两部分想成“备料”和“出餐”。知识入库是在备料;用户提问时的检索和回答是在出餐。没有备料,出不了餐;备料做得差,出餐也不会好吃。
向量数据库到底在做什么
很多教程会说“向量数据库会根据语义把相似内容放在一起”,这句话方向没错,但对初学者来说还是有点抽象。更容易理解的方式是:
当你把一段文本送进 Embeddings 模型时,模型不会输出一句“这段文字讲的是财务”或者“这段文字讲的是品牌”。它输出的是一串数字。这串数字本身对人类没有可读性,但它保留了语义上的关系。意思相近的文本,在向量空间里通常会更接近;意思差得远的文本,则会离得更远。
例如:
- “公司使命”
- “品牌愿景”
- “我们为什么存在”
这几类表达,字面上不完全一样,但语义接近,所以被转换成向量后,会在向量空间里相对靠近。
反过来:
- “退款政策”
- “服务器部署”
- “员工请假制度”
这些主题差异就比较大,彼此距离通常也会更远。
因此,向量检索的价值不在于关键词匹配,而在于它能处理“用户问法和原文写法不完全相同”的情况。这就是为什么 RAG 往往比传统全文搜索更适合自然语言问答。
分块不是附属步骤,而是决定效果的关键步骤
文档入库时最容易被低估的,就是 chunking(分块)。
你几乎不会把整篇 PDF 作为一个整体直接做向量化,因为那样有几个明显问题:
- 一整篇文档里通常包含多个主题,语义太混杂
- 检索时很难精准命中局部信息
- 一次召回整篇内容会让上下文冗长、成本变高、回答变乱
所以你需要把文档切成较小的文本块。每一个块,都会对应一个向量。
理想的块通常具备两个条件:
- 它只围绕一个相对集中的主题
- 它又保留了足够的上下文,单独取出来也能看懂
如果块太大,会出现一个块里同时包含“公司背景、财务说明、市场策略、售后政策”等多种信息。用户问“退款”,系统虽然可能召回了那个块,但模型还要在一大堆无关内容里找答案,效果自然下降。
如果块太小,比如切到只剩下一两句话,可能又会丢失必要上下文。用户问“这个规定适用于什么情况”,召回片段里只有“不得进行练习挥杆”,却没有上一句说明的适用条件,这种回答就容易缺胳膊少腿。
对于第一次搭建,最务实的做法不是一上来就追求“完美块大小”,而是:
- 先用 n8n 节点的默认或较稳妥配置跑通
- 再用真实问题测试召回质量
- 根据结果迭代调整块大小和切分方式
也就是说,先把系统做对,再把系统做细。
一个非常重要但常被忽略的规则:入库和查询必须使用同一种 Embeddings 模型
这不是“建议”,而是几乎可以视为稳定效果的硬规则。
原因很简单:
- 文档块在入库时,会被某个 Embeddings 模型转换成向量
- 用户问题在查询时,也会被某个 Embeddings 模型转换成向量
只有当两边使用的是同一套语义空间,向量之间的距离才有稳定意义。如果你用 A 模型把文档入库,再用 B 模型处理查询,虽然从流程图上看一切都连上了,但实际召回质量很可能明显变差,甚至出现“系统能回答但总是答偏”的情况。
因此,你在 n8n 里做配置时,必须明确这一点:
- 文档嵌入用什么模型
- 查询嵌入也必须用同一个模型
- 如果你后续想切换模型,最好重新入库,而不是在旧向量数据上混用
这是很多初学者最容易掉进去的“隐性坑”。因为它不会像凭证错误那样直接报错,而是表现为“为什么这个系统看起来正常,但回答总不太对”。
记忆不是 RAG,RAG 也不是记忆
这是第二个必须提前讲清楚的概念。
在智能体系统里,RAG 和 Memory(记忆) 解决的是两类不同问题:
- RAG 解决“模型如何查外部资料”
- 记忆解决“模型如何记住刚刚聊过什么”
举个简单例子:
如果用户说:“你好,我叫 Nate。”
过一会儿又问:“我叫什么名字?”
这不是去向量数据库查制度文档的问题,而是会话记忆问题。
再比如用户问:“公司的退款政策是什么?”
这通常不是靠聊天上下文记住的,而应该从事先入库的制度、文档或知识手册中检索出来。这就是 RAG 的职责。
所以,一个真正好用的企业助手,经常需要两者都具备:
- 用 RAG 查“长期知识”
- 用 Memory 记“当前会话”
如果把这两件事混为一谈,就会导致架构设计混乱,也很难排查问题。
在开始配置前,先准备好三个基础服务
这套方案虽然是无代码,但不是“零配置”。你至少要把三个基础部分准备好。
1. n8n:负责把节点连接成工作流
n8n 在这里扮演的是中控台。你会在里面拖拽并连接:
- 文档来源节点
- 数据加载/分块节点
- Embeddings 节点
- Supabase 向量存储节点
- 聊天触发器
- 智能体节点
- PostgreSQL 记忆节点
对于新手来说,n8n 的好处在于可视化。你可以很清楚地看到“数据从哪里来,去了哪里,中间经过了什么”。但也正因为是可视化,很多人容易产生错觉:节点能连上,不代表逻辑就对了。所以后面每走一步,都要验证输入输出是不是符合预期。
2. Supabase:既做向量库,也可以承载短期记忆
这套搭建中,Supabase 不只是简单的数据库托管。它至少可能承担两类角色:
- 存放向量数据,用于语义检索
- 通过 PostgreSQL chat memory 存放聊天历史
这也是为什么在创建 Supabase 项目时,你不能只想着“我先拿个 URL 和 key 就完事”。你还必须认真保存 数据库密码,因为后面配置 PostgreSQL 记忆时还要用到它。
非常实用的建议:
- 如果这是你的第一个 RAG 实验,单独建一个项目
- 项目名尽量清晰,例如
rag-dev、kb-test、agent-lab - 不要把实验数据、正式业务数据和别的项目混在一起
3. OpenAI API:用于 Embeddings 和模型回答
你需要配置可用的 OpenAI API 凭证,至少服务两类调用:
- Embeddings
- 聊天/回答模型
实践上建议:
- 在 n8n 里把凭证命名清楚,例如
OpenAI-RAG-Dev - 如果你会做多个实验环境,名称里加
dev、staging、prod之类的后缀 - 不要让不同节点“看起来都能用”,但实际上绑到了不同账号或不同用途的 key 上
这样排查成本会低很多。
第一步:先把知识入进向量库
整个系统第一段要解决的问题只有一个:让文档进入可检索状态。
先选一份适合测试的文档
第一次搭建时,最忌讳的就是上来就丢一大堆乱七八糟的数据。你应该故意选择一份“自己知道答案”的测试文档,这样你才能判断系统到底是流程不通,还是回答不准。
适合第一次测试的文档包括:
- 一份 FAQ
- 一份公司简介和政策说明
- 一份结构清晰的操作手册
- 一份条目式规则文档
不适合第一次测试的文档包括:
- 大量扫描件 PDF
- OCR 质量很差的文档
- 混合几十种主题的文件夹
- 字很少、图很多的演示文稿
为什么这么强调这个选择?因为在系统早期,你应该先验证“工作流逻辑”,而不是让自己陷入“源数据质量”和“系统配置问题”混合交错的泥潭里。
配置文档来源和加载节点
视频示例中使用的是 Google Drive 作为文档来源。你不必拘泥于来源一定相同,但逻辑要一致:
- 先能读取到文件
- 再把文件内容以文本形式传给后面的节点
你要检查的是:
- 凭证是否有文件读取权限
- 节点输出的是不是正文内容,而不只是文件名、时间戳、ID 这种元数据
- 如果是 PDF,提取出来的文字是否可读
一个非常常见的问题是:
工作流“看起来”已经拉到了文件,但实际上后面拿到的是二进制或元信息,而不是可用于分块的文本。此时从表面看流程没报错,但 Embeddings 和入库质量会直接崩掉。
配置分块
在 n8n 中,分块可能由文档加载器自带,也可能由独立的处理节点完成。无论具体形式怎样,你都应该带着以下标准去判断分块是否合理:
- 一个块是不是基本围绕一个主题
- 这个块单独被召回时,能不能大致读懂
- 用户的问题有没有可能语义上命中这个块
你不需要第一天就把 chunk size、overlap 调到极致,但一定要明白:
- 太大,检索不准
- 太小,语境不够
- 切错,后面所有节点都只能“在错误材料上努力工作”
第二步:配置 Embeddings 和向量写入
分块完成后,下一步就是把每个块转换成向量,再写入 Supabase。
Embeddings 节点的作用
Embeddings 节点并不负责“回答问题”,它负责把文本变成向量。你可以把它理解成“把人类可读文本,翻译成可做语义距离计算的数学表示”。
这里的关键配置决策有三个:
- 选定一个稳定的 Embeddings 模型
- 后续查询也用同一个模型
- 不要在第一次搭建时混用不同服务商的嵌入策略
如果你后期真的要切换模型,正确做法通常是:
- 明确版本变化
- 重新跑一遍入库流程
- 不要把新旧向量数据无序混在一起
写入 Supabase 向量存储
Embeddings 生成完成后,Supabase 节点要负责把这些向量写进去。
这时你需要确认:
- 连接的是正确的 Supabase 项目
- 写入目标是正确的向量表或目标存储配置
- 节点执行成功
- 如果支持元数据,尽量一起写入来源信息
元数据非常有用。比如你可以附带:
- 文件名
- 文档标题
- 来源路径
- 章节名
这样当你后面排查“为什么召回错了”的时候,你不只是看到一段内容,而是能知道它来自哪份文档、哪个位置,定位效率会高很多。
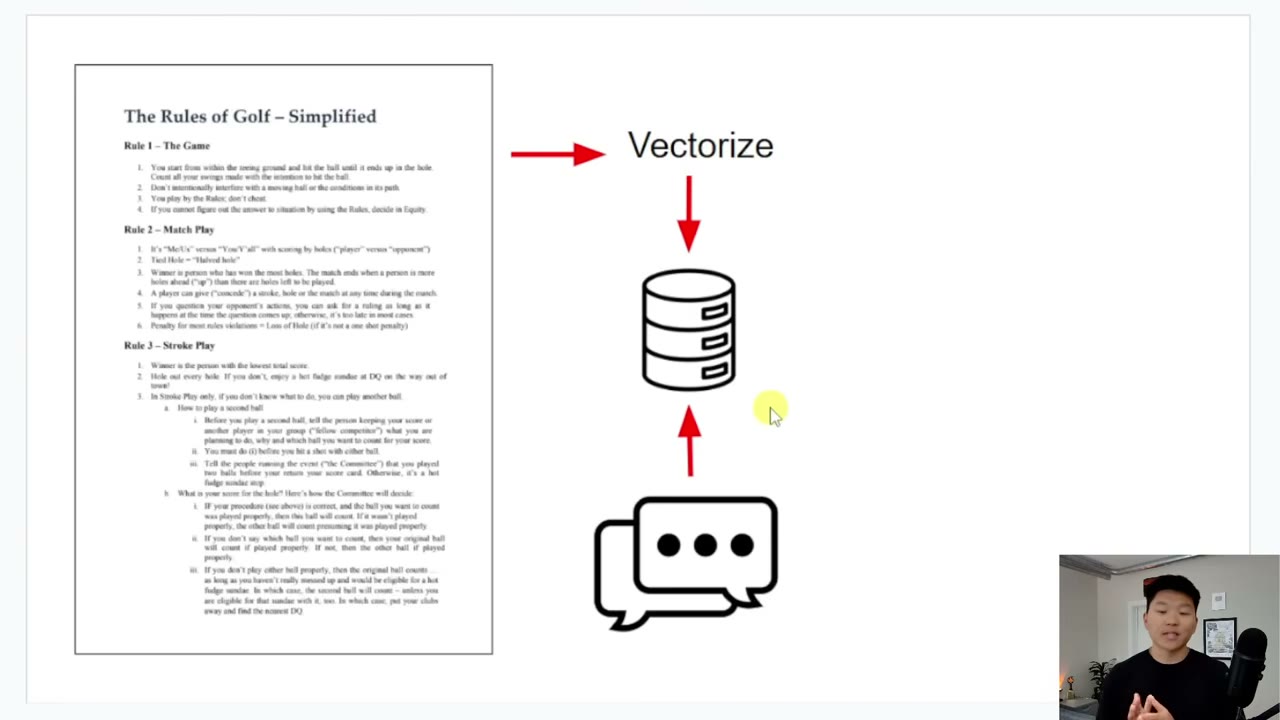
这个截图标记放在这里最合适,因为这一阶段对应的正是“整体工作流长什么样、文档怎么进入系统、节点如何串起来”的关键解释点。此时读者应该已经能从流程结构上说清:哪个节点负责拿文档,哪个节点负责分块,哪个节点负责 Embeddings,哪个节点负责把内容写进向量库。
第三步:把 Supabase 凭证配对,尤其要注意 PostgreSQL 记忆连接
很多新手不是栽在概念上,而是栽在凭证配置上。尤其是用 Supabase 同时做向量存储和 PostgreSQL 记忆时,两个连接虽然都与 Supabase 有关,但并不一定使用同样的字段或同样的连接方式。
向量存储凭证
Supabase 向量相关节点通常会要求你按该节点预期的方式填写项目信息,例如项目地址、密钥或相关连接参数。这里最重要的是确认你使用的是当前项目的正确配置,而不是顺手填了另一个环境的数据。
PostgreSQL Chat Memory 凭证
后面给智能体增加短期记忆时,你要配置的是 PostgreSQL 凭证。这时应进入 Supabase 的 Connect 页面,查看用于数据库连接的参数。
你通常需要这些值:
- Host
- Database
- User
- Password
- Port
在示例流程里,数据库名保持为 postgres,并且连接参数来自 transaction pooler 区域。这一步最容易出现的坑包括:
- 复制错了 host
- 忘了密码其实是你创建项目时自己设置的数据库密码
- 端口仍然沿用默认值,没换成 Supabase 给你的 pooler 端口
- 以为 Supabase 向量节点能连通,就代表 PostgreSQL 记忆节点也会自动通
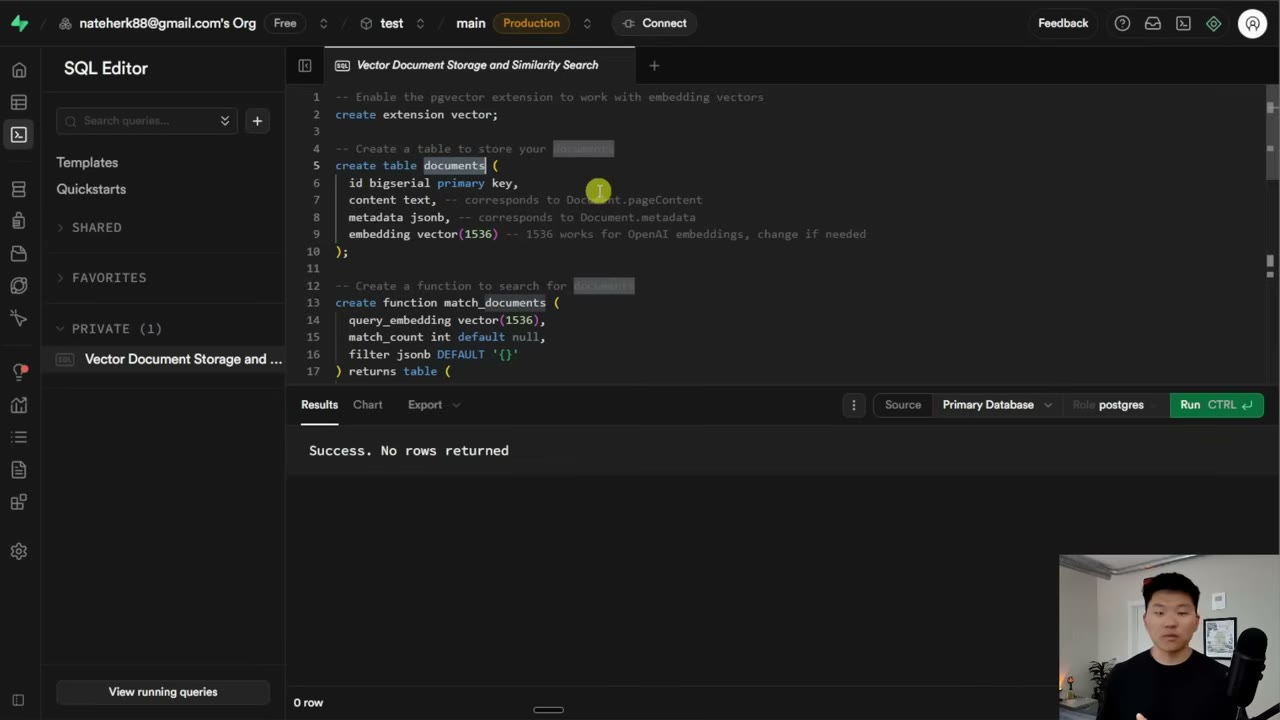
这个截图标记适合放在凭证设置讲解附近,因为这里的出错概率非常高,而且一旦配错,系统表面上可能只是“记忆不好用”,实际上根因是连接从一开始就没建立成功。
一个很务实的建议是:
如果连接测试没有变绿,就不要继续往后堆配置。先把连接测通,再说下一步。否则你只会把后续问题叠加在一个本来就断掉的基础上。
第四步:开始搭建真正回答问题的 RAG 智能体
当知识已经进入向量库后,第二段工作流才开始有意义。这一段的目标不是“存知识”,而是“在收到问题时用知识回答”。
配置聊天触发器
聊天触发器就是用户入口。它接收问题,然后把问题送进智能体流程。
第一次搭建时,建议保持克制:
- 先只做最小可用问答
- 不要一开始就接太多工具
- 先保证“问得到、查得到、答得出”
一个最小可用成功标准是:
- 用户提出一个与文档相关的问题
- 系统能从向量库召回正确片段
- 模型回答时明显使用了该片段内容,而不是胡乱编造
给查询做 Embedding
用户问题进入后,也必须先走 Embeddings,原因前面已经解释过:你要把问题放进同一个语义空间里,才能与文档块进行相似度匹配。
这里再次强调一致性:
- 文档入库用什么 Embeddings 模型
- 查询也必须用同一个
否则系统会进入一种很迷惑的状态:流程不报错,但命中总不精准。
连接 Supabase 向量检索
查询向量生成后,Supabase 会根据相似度返回最接近的问题相关块。你在这一阶段需要观察的不是“有没有返回东西”,而是:
- 返回了几个块
- 返回的块是否真的相关
- 是否过宽或过窄
例如,用户问“公司使命是什么”,结果召回的是“付款方式”“税务说明”“品牌主色彩”这些内容,那说明问题不在“模型不会答”,而是根本没把对的内容找回来。
反过来,如果召回内容已经很准确,但最后输出仍然答偏,那问题就更可能出在提示词或模型生成阶段。
让模型基于召回内容作答
一旦检索完成,模型就会同时看到:
- 用户原始问题
- 召回的知识片段
- 你给它的系统指令或智能体设定
这里建议给模型一个明确的工作边界:
- 优先根据召回内容回答
- 如果召回内容不足以支撑答案,就明确说明信息不足
- 尽量不要把没有依据的内容“补全成正确答案”
一个示意性的提示词思路可以是:
优先依据检索到的上下文回答问题。如果上下文中没有足够信息,请明确说明资料中未提供该答案,不要自行编造。
这只是说明思路的示例,不是固定模板。你可以按你的应用场景调整措辞,但原则不要变:宁可诚实地说不知道,也不要把 RAG 做成“看起来会查资料,其实还在幻觉”的系统。
第五步:测试时不要只问一个“标准答案题”
很多人搭完以后只问一句“这个 PDF 讲了什么”,系统答出来了,就认为成功。这种测试强度远远不够。
你至少应该准备四类问题:
1. 直接事实型问题
例如:
- “公司 X 的使命是什么?”
- “该规则允许做哪些练习?”
这类问题主要测最基础的召回准确性。
2. 同义改写型问题
例如:
- “这家公司为什么存在?”
- “它主要倡导什么价值?”
这类问题测的是语义检索能力,而不是关键词命中。
3. 越界问题
例如:
- “企业版合同退款期限是多少?”
如果文档里根本没有这个信息,系统理想行为应该是老实承认资料不足,而不是凭印象编一段听起来很像真的话。
4. 多轮追问
例如前一轮刚问完规则,下一轮问:
- “所以我不能在洞与洞之间打练习球吗?”
这类问题非常适合检验记忆是否起作用,也能帮助你区分:系统是在重新检索,还是在利用聊天上下文。
学会看日志,别靠猜
n8n 一个很大的优势是你可以看到执行细节。只要你愿意点开 logs,就能知道系统到底发生了什么,而不是只盯着最后一句回答。
在一个典型的 RAG 问答过程中,你应该能在日志里看出这些轨迹:
- 用户问了什么
- 查询被送去做了 Embedding
- 系统拿什么查询词去做向量相似检索
- Supabase 返回了哪些内容块
- 模型最终是如何组合出答案的
这一步非常关键,因为它能帮你区分三类不同故障。
故障一:检索故障
现象:系统答错了,但其实是因为召回内容本身就不对。
常见原因:
- 文档切分不合理
- Embeddings 模型前后不一致
- 源文本提取质量差
- 数据集太杂,噪音太多
故障二:生成故障
现象:召回内容是对的,但模型总结时答偏了、答漏了、答得过度发挥。
常见原因:
- 系统指令太弱
- 召回上下文过多,模型抓不住重点
- 使用的模型不适合这类整理与回答任务
故障三:记忆故障
现象:当前问题能答,但对刚才聊过的内容没有连续性,像每次都当成第一次见面。
常见原因:
- 没有配置记忆
- 记忆连接未真正生效
- 记忆配置存在但没有被当前工作流正确调用
一旦你学会这样分层排查,就不会陷入“AI 玄学调参”。你会非常清楚:是资料没找对,还是模型没说好,还是压根没记住上下文。
第六步:加上 PostgreSQL 记忆,让智能体真正像在“对话”
如果不加记忆,这个智能体仍然可以做问答,但体验会更像一个“每次都只答单轮搜索”的工具。很多场景下这并不够。
例如用户先说:
- “你好,我叫 Nate。”
再问:
- “我叫什么名字?”
如果没有记忆,系统可能不会直接知道;即使它重新去向量库查,也查不出用户刚才那句话。因为那不是文档知识,而是会话上下文。
为什么这里适合用 PostgreSQL Chat Memory
因为你已经用上 Supabase 了,它本身就是 PostgreSQL 生态的一部分。此时继续把聊天记忆写入 PostgreSQL,是一种很自然的延伸,而不是再额外引入一种新的存储方式。
启用之后,系统可以存:
- 用户消息
- 智能体回复
- 多轮对话上下文
这意味着:
- 用户做追问时,系统更容易理解“它指的是上一个话题”
- 用户先提供了自己的名字、偏好、背景,后面系统能记住
- 一些不必重复检索的短期上下文,可以在会话中自然延续
但也必须再次提醒:
记忆不能替代 RAG。
如果问题指向的是文档、制度、规则、产品资料,还是应该依赖检索到的知识;记忆更多是为了让对话连续、自然、少重复。
PostgreSQL 记忆配置时要特别核对什么
在 n8n 里新增 PostgreSQL 凭证时,重点核对这些字段:
Host:从 Supabase Connect 相关参数中复制Database:示例中通常为postgresUser:使用 Supabase 提供的数据库用户名Password:这里用的是你创建项目时设置的数据库密码Port:使用 Supabase 提供的正确端口,例如 transaction pooler 对应端口
一个示意结构如下,仅作格式参考:
Host: <来自 Supabase 的连接参数>
Database: postgres
User: <来自 Supabase>
Password: <创建项目时设置的数据库密码>
Port: 6543
请注意,这只是演示结构示例。你实际填写时必须以自己项目中展示的值为准。
一个完整例子:从规则文档到可问答助手
为了把整个链路串起来,我们可以用一个具体场景理解。
假设你有一份关于高尔夫比赛练习规则的 PDF。系统入库阶段会做这些事:
- 读取 PDF 文本
- 按语义或长度拆成多个块
- 对每个块做 Embedding
- 把向量及相关内容写入 Supabase
这时用户发问:
What am I allowed to do for practice?
系统会:
- 把这句问话做 Embedding
- 去 Supabase 查最接近的规则块
- 找到讲“练习规则”的相关内容
- 把相关片段交给模型
- 输出基于规则原文的回答
如果用户接着问:
So I can’t hit a practice shot between holes?
这时你就能观察到两种不同系统行为:
- 如果没有记忆,它很可能又去做一次检索
- 如果有记忆,它更容易把这句理解为对上一轮问题的追问,并结合会话上下文给出更自然的回答
这就是为什么一个“能查资料”的系统,不一定等于一个“会聊天的助手”;而加上记忆后,两者才真正组合起来。
真正能上线前,必须做的几项具体决策
很多教程到“跑通了”就结束了,但如果你想把这个系统用于真实工作,还要提前做一些很具体的决定。
决定你的“事实来源优先级”
当聊天上下文与文档知识不一致时,系统该相信谁?
比较稳妥的业务规则通常是:
- 用户刚刚说的个人偏好、身份信息,优先来自会话记忆
- 企业规则、产品说明、制度条款,优先来自检索到的正式文档
- 如果两者冲突,文档知识应优先于模糊记忆或猜测
这条原则不写清楚,后续很容易出现“智能体看起来很顺畅,但其实把用户随口一句话当成制度依据”的风险。
决定第一批知识范围不要过大
上线前第一版,最好只覆盖一个狭窄主题。
例如:
- 只做 HR 手册问答
- 只做产品安装说明问答
- 只做售后政策问答
而不要第一版就把公司所有知识一股脑全部塞进去。因为范围太大时,你很难判断问题到底来自:
- 检索设计不佳
- 数据源太乱
- chunking 不合理
- 文档本身不适合做问答
先把一个窄域跑稳,比一开始追求“大而全”更实际。
决定如何重建索引
文档会更新,这件事一定会发生。所以你必须提前想好:
- 文档更新后是否要重新跑入库流程
- 同名文档更新时如何避免旧向量和新向量混杂
- 是否保留版本信息或来源元数据
如果你不提前设计这些,系统上线后很快会出现“为什么它答的是旧政策”的问题。
初学者最常见的坑,和对应的修正方法
坑一:以为 RAG 效果差,其实是源文本就已经很脏
如果 PDF 提取出来的正文顺序错乱、断词严重、表格全坏,后面的 Embeddings 和向量检索再努力,也只能在坏数据上做近似搜索。
修正方法:
- 先检查提取后的纯文本质量
- 第一次搭建尽量使用干净文本源
- 如果是 PDF,优先确认内容是否可读
坑二:查询与入库 Embeddings 不一致
这是前面讲过但值得再说一次的高频坑。
修正方法:
- 固定使用同一个 Embeddings 模型
- 变更模型后重新入库
- 不要在同一个知识库里无规划混放不同嵌入策略生成的向量
坑三:把向量库当成聊天记忆
向量库擅长找知识,不擅长替你维护一段自然会话中刚说过的人名、偏好和上下文状态。
修正方法:
- 文档知识走 RAG
- 对话上下文走 Memory
- 两者分工明确
坑四:只测“标准题”,不测边界题
如果你只问那些原文里措辞几乎一模一样的问题,系统很容易显得很聪明。但真实用户不会只这样问。
修正方法:
- 加入改写问题
- 加入越界问题
- 加入多轮追问
- 加入资料中本就没有答案的问题
坑五:凭证命名混乱
n8n 里一旦凭证多起来,很容易出现“这个节点能跑,但到底连的是哪个项目”的问题。
修正方法:
- 用明确命名,如
Supabase-RAG-Dev、Postgres-Memory-Dev、OpenAI-RAG-Dev - 一个环境一套命名规则
- 不要让多个凭证都叫默认名
最后的操作检查清单
在你把这套流程视为“已经可用”之前,至少把下面这些项逐条确认一遍:
- 文档源可稳定读取,且提取出的文本可读。
- 分块后的样本抽查是连贯的,不是破碎文本。
- 文档入库与用户查询使用的是同一个 Embeddings 模型。
- Supabase 向量写入确实成功,不是只有节点连线成功。
- 至少 3 个直接事实问题可以答对。
- 至少 3 个改写问法也能召回正确内容。
- 至少 1 个超出资料范围的问题会被诚实拒答,而不是被编造回答。
- 日志中能看见召回了哪些内容块。
- PostgreSQL chat memory 的连接测试已成功。
- 多轮对话中,系统能记住短期会话上下文,例如用户名字。
- n8n 里的凭证名称清晰,没有多个用途不明的重复配置。
- 你已经知道文档更新后如何重新入库,而不是等数据过期后再临时补救。
你接下来真正该优化什么
当第一版跑起来后,很多人会立刻想加更多功能,例如更多工具、更多模型、更多触发方式。但从工程角度看,第一阶段最值得优化的,往往不是“加法”,而是把已有链路做扎实。
优先优化这些层面:
- 提升源文档质量
- 调整 chunking 策略
- 明确回答边界,减少幻觉
- 给向量数据附带更清晰的来源元数据
- 缩小知识域,让召回更纯净
- 设计更严格的测试问题集合
一个可靠的 RAG 智能体,不是因为用了多少新名词,而是因为你知道每一层为什么存在、出了问题该看哪里、以及系统在什么边界内可以被信任。
来源说明:本文基于 Nate Herk | AI Automation 的视频教程《From Zero to RAG Agent: Full Beginner's Course (no code)》及其提供的元数据与节选字幕整理写作。原始链接:https://www.youtube.com/watch?v=cCD303XsUjI