为什么你会在 LangChain 之后需要 LangGraph
很多人第一次接触大模型应用开发时,都是从“提示词 + 模型调用 + 输出结果”这种直线式流程开始的。比如公司知识库问答、客服 FAQ 机器人、基于固定文档回答问题的内部助手,这类任务通常输入清晰、步骤固定、控制流简单,LangChain 往往已经够用。
但一旦你的应用不再是“问一次、答一次”这么简单,问题就会出现。你可能需要:
- 根据中间结果决定下一步要走哪条路径
- 反复迭代同一个流程,直到满足某个条件才停止
- 在多个步骤之间共享上下文,而不是每步都重新拼接输入
- 调用多个工具,并根据工具返回值分支处理
- 记录当前处理到哪个来源、哪些来源已通过筛选、哪些被丢弃
这时候你面对的就不再是一个普通链式调用问题,而是一个“工作流编排问题”。LangGraph 的价值,正是在这里开始体现。
可以用一句很实用的话来区分两者:
- 如果你的任务主要是顺序执行、逻辑确定、流程短,优先用
LangChain。 - 如果你的任务需要状态、条件路由、循环、记忆、工具协同或多步代理行为,优先考虑
LangGraph。
初学者最容易踩的坑,是明明业务已经复杂到需要工作流编排了,却还在普通 Python 代码里手写 if/else、for 循环、重试逻辑、工具调用顺序和状态管理。这样做不是不能跑,而是很快会变得难维护、难测试、难解释。最终你会发现,复杂的不是业务本身,而是你为了“把流程粘起来”写出的那一堆控制代码。
LangGraph 的作用,就是把这些原本分散在代码各处的流程控制,提升为一个可视、可推理、可维护的图结构。
先把脑图搭起来:节点、边和共享状态
理解 LangGraph,核心不是先记 API,而是先建立它的思维模型。
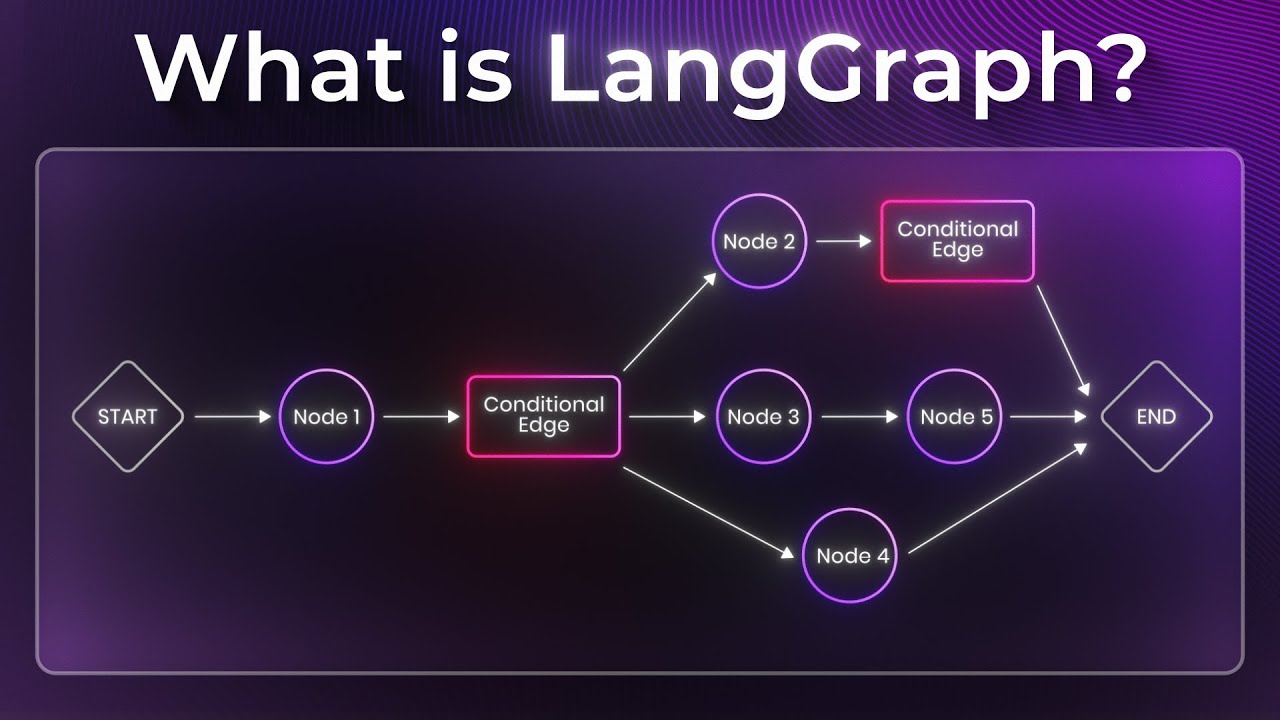
它最重要的基础结构叫 StateGraph。
在 StateGraph 里,有三个你必须彻底理解的概念:
node:节点,表示一个独立的计算单元,通常就是一个函数edge:边,表示执行从一个节点流向另一个节点的规则state:状态,表示整个工作流共享、持续存在的数据
节点是什么
节点可以理解成“只做一件事的小工序”。
例如在一个研究助手里,节点可以分别负责:
- 搜索信息源
- 抓取网页正文
- 清洗页面内容
- 评估信息可信度
- 提取事实陈述
- 汇总生成报告
每个节点都不应该包揽太多职责。节点越单一,图的行为越容易调试和替换。
边是什么
边决定“下一步去哪里”。
LangGraph 里常见有两类边:
- 普通边:固定流向下一个节点
- 条件边:根据当前状态决定下一步走向
比如:
- 如果当前网页可信度高于 75,进入“提取事实”节点
- 如果低于 75,直接跳过,处理下一个来源
- 如果已经没有剩余 URL,结束循环并生成报告
也就是说,边不只是连线,它本质上是业务决策路径。
状态为什么是 LangGraph 的灵魂
真正把 LangGraph 和普通链式调用拉开差距的,是 state。
状态不是某个函数的局部变量,而是整个图共享的一份“工作记忆”。所有节点都可以读取它,节点运行后也会把结果写回状态。这样,下一个节点不需要靠你手动传十几个参数,也不需要从零拼上下文,它只需要读取当前状态即可。
一个研究助手最基础的状态可以这样设计:
from typing import TypedDict, Optional, List
class ResearchState(TypedDict):
topic: str
remaining_urls: List[str]
current_url: Optional[str]
content: Optional[str]
current_score: Optional[int]
facts: List[str]
report: Optional[str]
这几个字段分别代表:
topic:当前研究主题remaining_urls:还没处理的链接列表current_url:当前正在处理的链接content:当前网页清洗后的正文current_score:当前来源的可信度评分facts:已提取出的事实列表report:最终生成的报告
初学者要真正理解的一点是:LangGraph 并不是“给 LangChain 再套一层壳”,而是把复杂应用的控制逻辑变成了一个显式的状态图。只要这一步想通了,后面的节点、分支、循环、记忆都会顺起来。
用研究助手这个案例,理解 LangGraph 到底解决了什么问题
视频里最有代表性的例子,是构建一个深度研究助手。这个场景非常适合拿来入门,因为它既不抽象,也足够体现 LangGraph 的价值。
假设你的需求是:围绕某个主题,自动搜索多个来源、阅读内容、筛选可信信息、抽取事实,最后生成一份结构化报告。
比如研究主题是:Tesla earnings call。
一个比较真实的业务要求可能是:
- 先去网页上搜索相关资料
- 收集博客、论坛、新闻、研究文章、社交内容等不同来源
- 逐个读取和理解这些来源
- 判断每个来源是否足够可信
- 只有评分超过
75的内容才能进入后续分析 - 从可信来源里抽取可验证事实
- 最终整理成一份报告
如果不用 LangGraph,大多数人会直接写一长串流程代码:
- 调搜索 API 获取链接
- 遍历链接列表
- 抓网页内容
- 把网页内容送进大模型评估
- 解析评分结果
- 超过阈值的留下来
- 把可信事实整理成报告
这套流程当然能写出来,但痛点马上会出现:
- 你要自己管理当前处理到第几个 URL
- 你要自己维护“剩余 URL 列表”
- 你要自己决定某个来源是否需要跳过
- 你要自己处理抓取失败、空页面、评分失败等异常路径
- 你要自己决定何时结束循环
- 你要确保最终报告只用可信信息,而不是把原始噪声一股脑送进去
这类问题,真正复杂的不是单个函数,而是“如何编排这些函数的运行顺序和状态传递”。LangGraph 正是把这层复杂度抽象掉。
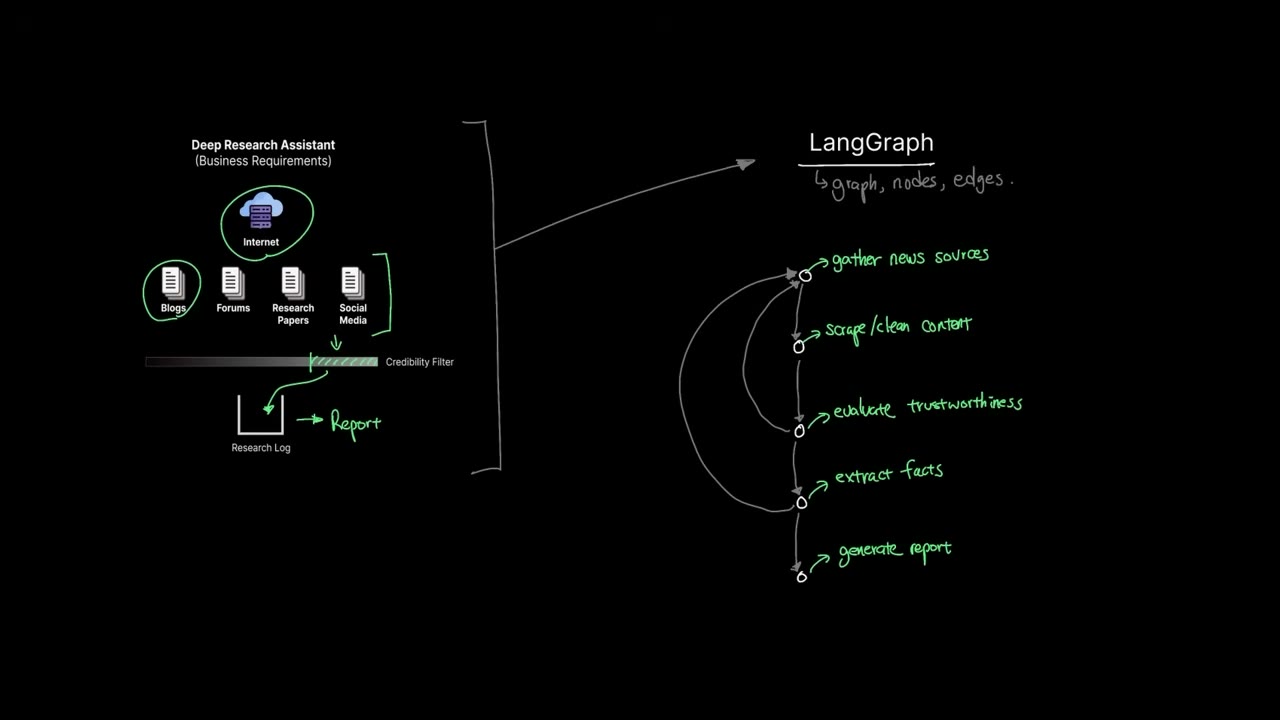
在 LangGraph 里,这个研究助手会被拆成一组明确节点:
gather_sources:搜索并收集来源load_next_source:取出下一个要处理的链接scrape_and_clean:抓取并清洗正文evaluate_trustworthiness:评估可信度extract_facts:抽取事实generate_report:生成报告
再配上几条关键决策规则:
- 如果
remaining_urls为空,就停止循环并进入报告生成 - 如果
current_score小于阈值,就跳过事实提取 - 如果还有链接待处理,就继续回到下一轮处理
你会发现,业务逻辑本身一下就变清楚了。因为它不再藏在一堆嵌套控制语句里,而是直接体现在图结构上。
顺序链和有状态图,到底差在哪
很多初学者第一次听“Stateful Workflow”会觉得有点抽象。其实一个非常小的对比例子就够了。
设想你有三个步骤:
- 第一步:向 Alice 打招呼
- 第二步:向 Alice 道别
- 第三步:问模型还记不记得刚才那个人叫什么
如果你是用普通顺序链,而且每一步都彼此独立,那么第三步很可能答不上来,因为这个流程并没有真正共享“名字”这个信息。每步只是独立调用模型,模型并没有在工作流层面保留状态。
但如果你用 StateGraph,把 name="Alice" 放进状态里,后面的节点就可以继续访问它:
- 道别节点可以明确说出 Alice 的名字
- 记忆检查节点也能正确读取这个名字
这就是最本质的区别:
- 链更像“把上一步输出传给下一步”
- 图更像“所有步骤都围绕同一份状态协作”
在小例子里,这种差别只是“能否记住 Alice”。但在真实系统里,这种差别会决定你的应用能不能稳定处理循环、分支、工具调用、评分、过滤和多步结果累积。
真正开始编码前,先把环境和依赖想明白
想快速上手一个可跑的 LangGraph 实验环境,一般会安装几类依赖:
langgraphlangchainlangchain-corelangchain-communityduckduckgo-searchbeautifulsoup4langchain-openai
一个代表性的安装命令可以写成:
# 示例命令
pip install langgraph langchain langchain-core langchain-community \
duckduckgo-search beautifulsoup4 langchain-openai
这里有几个新手特别容易忽略的配置点。
搜索工具为什么很关键
如果你只是想理解 LangGraph 的工作流,不想一开始就被商业搜索 API 的密钥、额度和计费卡住,duckduckgo-search 是一个不错的入门选择。它的好处不是“能力最强”,而是启动成本低,足够让你把注意力放在图的执行逻辑上。
但要明确:搜索工具只是输入来源,不等于信息质量保证。搜索出来的 URL 越杂,你后面的筛选节点压力越大。
网页抓取不能把原始 HTML 直接送模型
很多初学者会在抓到网页之后直接把整个 HTML 扔给模型,这是非常低效的做法。
至少要先做几步清洗:
- 去掉
script、style等无关标签 - 合并多余空白和换行
- 截断超长内容,避免一次喂太多 token
- 保留来源 URL,便于后续引用和审计
如果这一步做不好,后面的可信度评估和事实提取都会变差,因为模型接收到的是噪声而不是正文。
模型配置错误,经常会被误判成 LangGraph 问题
如果你使用 langchain-openai,先单独验证以下项目:
- API Key 是否正确
base_url是否正确,尤其在使用代理或兼容网关时- 模型名称是否有效
- 超时时间是否足够
- 长文本输入是否会触发 token 限制
很多人一看到图跑不通,就以为是 LangGraph 的节点或路由有问题。实际上,最常见的故障来自模型客户端配置不正确,或者某个工具调用本身就没成功。
先设计状态,再写节点,顺序不要反
普通脚本开发里,很多人习惯先写函数。但在 LangGraph 里,这通常不是最高效的顺序。
更推荐的流程是:
- 先明确最终业务目标
- 再列出达成目标需要保存哪些状态
- 再定义每个节点负责读写哪些状态
- 最后才定义节点之间如何路由
对于研究助手,一个更实用的状态设计可以像这样:
from typing import TypedDict, Optional, List, Dict
class ResearchState(TypedDict):
topic: str
remaining_urls: List[str]
visited_urls: List[str]
current_url: Optional[str]
content: Optional[str]
current_score: Optional[int]
accepted_facts: List[str]
rejected_sources: List[Dict[str, str]]
report: Optional[str]
status: str
比最小版本多出的字段都有明确意义:
visited_urls:避免重复处理同一链接accepted_facts:把最终可用事实与原始内容分开rejected_sources:记录被丢弃的来源和原因,便于审查status:快速反映当前工作流处于哪个阶段
状态设计过少,后续节点会互相“借变量”,流程容易脆弱。状态设计过多,则会让提示词冗长、图结构混乱。正确做法不是把所有东西都塞进状态,而是只保留后续节点和运维排障真正需要的信息。
从零搭一个研究助手工作流
下面按实际开发顺序,把这个图拆开。
第一步:搜索候选来源
第一个节点接收主题 topic,去搜索若干相关链接。
它至少要做三件事:
- 执行搜索
- 标准化 URL
- 去重并限制结果数量
这里有一个非常实际的经验:不要一开始就让图处理几十个来源。那会迅速放大时延、成本和噪声。入门版本建议只保留 3 到 8 个结果。
这个节点典型的输出更新是:
- 填充
remaining_urls - 更新
status为sources_found
第二步:取出下一个来源
这个节点负责从 remaining_urls 中拿出一个链接,写入 current_url,并同步更新剩余列表。
这一步非常重要,因为它把“迭代”显式地放进了图里,而不是在图外写一个 Python for 循环。换句话说,不是外层代码在驱动流程,而是图自己掌控流程推进。
这个节点通常会:
- 设置
current_url - 更新
remaining_urls - 把当前 URL 加进
visited_urls
第三步:抓取并清洗网页内容
这个节点读取 current_url,抓网页正文并做清洗,输出到 content。
建议你在这一层就明确几个规则:
- 无法抓取时,要返回清晰的失败信号
- 抓到空页面时,不要继续送模型评估
- 对超长内容要截断或分块
- 清洗后的文本要尽量保留可读性,而不是拼成一大坨
如果你后续还要做证据引用,最好同时保留“内容来自哪个 URL”的对应关系,而不是只存纯文本。
第四步:评估可信度
这里是 LangGraph 开始体现业务价值的关键一步。
你不是简单地问模型“这篇内容靠谱吗?”,而是要设计一个可机器处理的评分输出。最少应该要求模型返回:
0到100的分数- 一句简洁理由
- 关键风险标记,例如:传闻、广告口吻、无作者信息、难以核验等
为什么不能只返回一段自然语言?因为下一个路由节点需要稳定地根据结果做判断。如果返回的是“我觉得还行”“看起来有一定可信度”这种模糊文本,你的分支逻辑会变得非常脆弱。
所以这一步最好输出结构化结果,再写入 current_score 或更细的评分字段。
第五步:按评分走条件分支
这里就是典型的条件边场景。
- 如果
current_score >= 75,进入extract_facts - 如果
current_score < 75,跳过这个来源,转去处理下一个 URL
这一步最能说明 LangGraph 和普通顺序链的区别。顺序链更像“所有来源都一视同仁走完整个流程”,而 LangGraph 则允许“根据状态动态决定是否继续深入处理”。这就是工作流编排,而不是单纯串调用。
第六步:从可信内容中提取事实
事实提取节点的目标,不是让模型写一段看起来合理的总结,而是抽取离散、明确、可引用的事实陈述。
好的事实长这样:
Tesla 报告了某季度营收为 X。本次财报电话会发生在日期 Y。管理层给出了 Z 方向的业绩指引。
不够好的输出长这样:
文章整体比较乐观。作者感觉公司未来不错。内容似乎暗示市场信心在增强。
这些是评论、倾向或印象,不是你最终报告应该依赖的“证据级信息”。
如果你希望最终报告更可追溯,可以把提取结果保存成“事实 + 来源 URL”的结构,而不是简单字符串列表。
第七步:循环处理直到来源耗尽
提取完事实后,图不会自然结束,而是要检查 remaining_urls 里是否还有待处理来源。
- 有,就回到
load_next_source - 没有,就进入
generate_report
循环是 LangGraph 的核心优势之一。你不需要在图外面再包一层循环逻辑,而是直接把“迭代直到耗尽输入”表达成图结构和状态转移。
第八步:生成最终报告
所有来源处理完之后,最后一个节点根据累积下来的可信事实生成报告。
这一层建议至少做到:
- 按主题或子问题组织事实
- 区分高置信事实和不确定信息
- 如果状态里保留了来源映射,最好在报告中体现出处
- 输出一个简洁结论,再给 supporting details
一个很关键的设计原则是:报告节点最好消费“已筛选、已提取”的事实,而不是重新把所有原始网页正文丢给模型。前者更稳定、更便宜,也更容易控制质量。
工具、路由、循环、记忆,到底怎么配合
很多人会把 LangGraph 理解成“可视化流程图工具”。这太低估它了。它真正强的地方,是把工具调用和状态驱动决策放在同一个执行框架里。
条件路由
条件边的作用,是让图根据状态回答“下一步该去哪”。常见判断包括:
- 还有没有未处理来源
- 当前评分是否达标
- 抓取是否成功
- 是否需要重试
- 是否应该直接结束
如果你的应用经常在问这些问题,那么它已经很接近 LangGraph 的适用范围了。
循环和迭代
研究类工作流天然需要重复处理多个对象,但每个对象未必走同一条路径。某些页面抓取失败,某些页面低可信,某些页面可以提取很多有效事实。LangGraph 把这种“重复中带分支”的流程表达得非常自然。
工具接入
在这个案例里,工具主要是:
- 搜索工具
- 网页抓取和解析工具
- 大模型本身
扩展到真实业务时,工具还可能包括:
- 向量数据库
- SQL 数据库
- 内部 API
- 文档解析器
- 计算器
- 企业知识平台
LangGraph 不负责替代这些工具,它负责决定:
- 什么时候调用它们
- 它们读取哪部分状态
- 它们把什么结果写回状态
- 下一步由谁接手处理
记忆和共享状态
这正是很多团队从“只用链”升级到“用图”的核心原因。因为节点不需要每次重新拼上下文、重新猜测系统进度。状态把主题、当前进度、当前来源、已接受证据、最终输出全部串联起来,让整个流程保持一致性。
代码结构应该长什么样
具体 API 版本会变化,但从结构上看,一个典型工作流通常会有这样的形态:
from langgraph.graph import StateGraph, START, END
workflow = StateGraph(ResearchState)
workflow.add_node("gather_sources", gather_sources)
workflow.add_node("load_next_source", load_next_source)
workflow.add_node("scrape_and_clean", scrape_and_clean)
workflow.add_node("evaluate_trustworthiness", evaluate_trustworthiness)
workflow.add_node("extract_facts", extract_facts)
workflow.add_node("generate_report", generate_report)
workflow.add_edge(START, "gather_sources")
workflow.add_edge("gather_sources", "load_next_source")
workflow.add_edge("load_next_source", "scrape_and_clean")
workflow.add_edge("scrape_and_clean", "evaluate_trustworthiness")
workflow.add_conditional_edges(
"evaluate_trustworthiness",
route_after_scoring,
{
"extract": "extract_facts",
"next": "load_next_source",
"report": "generate_report",
},
)
workflow.add_conditional_edges(
"extract_facts",
route_after_extraction,
{
"next": "load_next_source",
"report": "generate_report",
},
)
workflow.add_edge("generate_report", END)
graph = workflow.compile()
这里最重要的编程纪律是:节点尽量返回状态更新,而不是去修改散落在全局作用域里的变量。这样你的图才容易测试、容易重放、也容易观察每一步到底做了什么。
初学者最常见的坑
把状态当成垃圾桶
有些人为了“以后可能用得上”,把原始 HTML、清洗文本、提取事实、完整模型回复、调试日志全都塞进状态,最后状态越来越臃肿,提示词越来越长,路由判断也越来越难看懂。
更合理的做法是把不同层级的数据分开:
- 原始抓取结果
- 清洗后正文
- 结构化评分
- 事实清单
- 最终报告
不要让单个字段承担多种语义。
让模型返回纯自然语言,而不是结构化结果
如果后续逻辑依赖某个字段,比如是否大于 75,那么这个值就应该用结构化方式返回。否则你会被迫写大量脆弱的字符串解析逻辑。
节点职责混乱
“搜索 + 抓取 + 评分 + 写报告”全部塞进一个节点,看起来代码短,实际上会让 LangGraph 失去意义。图的价值就在于把复杂过程拆成可组合、可替换、可调试的小单元。
没有失败路径
现实环境里,失败才是常态。网页可能禁止抓取,页面内容可能为空,模型可能超时,返回结构可能不合法。如果图里没有“失败怎么办”的分支,流程一旦异常就会卡死或产生脏结果。
没有成本边界
一个看似简单的图,如果每处理一个来源都把超长文本原封不动发给模型,成本会非常快地失控。必须尽早控制:
- 来源数量上限
- 页面内容长度
- 提示词冗余
- 是否需要分块处理
什么时候企业应该认真考虑 LangGraph
不是所有 LLM 应用都需要 LangGraph。真正适合它的场景,通常有这些特征:
- 需要多个步骤共同完成任务
- 不同步骤依赖中间状态
- 要根据结果做分支决策
- 需要循环迭代而不是一趟结束
- 要协调多个工具而不是只调一个模型
- 希望工作流具备可审计性和可维护性
典型例子包括:
- 研究助手
- 文档审阅与比对流水线
- 带验证环节的客服代理
- 合规和政策检查系统
- 搜索、筛选、打分、汇总混合型自动化工作流
反过来说,如果你的应用只是“取回上下文 + 提示模型回答”,那大概率先用 LangChain 就够了。只有当你的系统不断出现“下一步该做什么”的决策需求时,LangGraph 才真正开始发挥优势。
最适合初学者的构建顺序
如果你准备自己动手做第一个 LangGraph 项目,不要一上来就追求“完整自治代理”。更稳妥的顺序是:
- 先做一个极小状态,只验证状态能跨节点保留
- 再加一个简单工具,例如搜索
- 再加一个条件分支,例如评分达标/不达标
- 再加一个循环,处理多个输入对象
- 最后再加综合输出节点,生成结果报告
- 做完主流程后,再补日志、错误处理和观测能力
这个顺序非常重要。因为很多新手失败,不是因为 LangGraph 难,而是因为一次性同时调试太多层面:模型、工具、提示词、状态、路由、循环、输出格式,全叠在一起,问题根本无法定位。
把图一层一层搭起来,才是最快到达可用版本的方法。
上线前的操作检查清单
在你把一个 LangGraph 工作流称为“可用”之前,至少逐项确认下面这些内容:
- 状态结构是否清晰、字段是否最小必要
- 每个节点是否只有一个明确职责
- 每一条条件边是否都基于可观察的状态字段
- 搜索结果是否做了去重和数量限制
- 网页内容是否经过清洗和长度裁剪
- 可信度评估是否返回结构化分数,而不只是自然语言描述
- 低质量来源、空页面、抓取失败是否都有跳过或失败分支
- 循环是否一定会在输入耗尽时终止
- 最终报告是否基于已提取事实,而不是原始网页大段内容
- 模型密钥、
base_url、模型名、超时配置是否单独验证过 - 是否能从日志或跟踪里看出每一步执行了哪个节点、为什么走到下一条边
- 对当前来源数量和页面长度来说,延迟与 token 成本是否在可接受范围内
如果这些都没问题,那么你做出来的就不只是一个能演示的玩具图,而是一个真正具备工程基础的有状态 AI 工作流。
来源说明
本文基于 KodeKloud 发布的 YouTube 教程 “LangGraph Explained for Beginners” 的核心内容整理,并扩展为可独立学习与实践的完整文字教程。原始视频链接:https://www.youtube.com/watch?v=cUfLrn3TM3M