
为什么智能体需要可恢复执行
OpenAI Agents SDK 已经把智能体开发里的许多关键抽象整理好了:可以定义 agent、工具、handoff、guardrail,也能接入 tracing。用它写一个本地原型很快,几行 Python 就能让模型调用工具并返回结果。但一旦进入生产环境,智能体通常不再是一次请求里完成的小脚本。它可能要爬网页、调用外部 API、等待用户补充信息、生成 PDF,甚至协调多个专门 agent 一起完成研究任务。
问题也从这里开始。如果进程在中途崩溃,普通脚本通常会丢掉当前状态。已经完成的搜索、已经花钱调用过的模型、已经生成到一半的报告,都可能需要从头再来。用户看到的是等待时间变长,系统承担的是重复计算和不可靠体验。Temporal 的价值就在这里:它把智能体的执行过程变成一个持久化工作流,让每个关键步骤都能被记录、恢复和重试。
这篇教程不要求你先看视频。你只需要理解一个核心思路:用 Agents SDK 表达智能体能力,用 Temporal 管理执行可靠性。agent 的决策流程放在 workflow 里,模型调用、网络请求、文件写入这类不稳定操作放在 activity 里。Temporal 负责记录历史、调度 worker、处理失败重试,并在进程恢复后继续执行。
整体架构:把智能体拆成工作流和活动
一个适合生产的结构通常包含四层。第一层是 Agents SDK 中的 agent 定义,包括角色指令、工具、handoff 和安全约束。第二层是 Temporal workflow,它描述这次任务的可靠执行流程。第三层是 Temporal activity,用来包住模型调用、网页搜索、数据库查询、PDF 生成等有副作用的操作。第四层是 worker,负责从 Temporal 的任务队列中取任务并真正执行。
这种拆法刚开始看起来比普通脚本多了一层,但它解决的是生产系统最疼的部分:任务中断以后怎么办。比如一个 deep research 智能体要根据主题做十几次搜索、汇总资料、生成报告。如果某次搜索超时,只需要重试那个搜索 activity;如果 worker 进程挂掉,workflow 本身不会消失;如果用户半小时后才回答澄清问题,workflow 仍然可以继续。
第一步:先确定 agent 的业务边界
不要一上来就把所有代码塞进 Temporal。先问清楚这个智能体到底承担什么业务任务。一个好的边界应该是用户能理解的结果,例如:输入一个研究主题,输出一份结构化报告;输入一个客服问题,输出解决方案和后续动作;输入一个代码库问题,输出调查结论和修改建议。
以研究智能体为例,你可以把它拆成规划 agent、搜索 agent、综合 agent 和报告生成工具。Agents SDK 负责表达这些角色之间的协作关系。Temporal workflow 负责串联这些步骤,并确保每一步失败后有恢复路径。
workflow 的输入应该保持小而清晰,比如主题、用户偏好、输出格式、请求 ID。不要把数据库连接、HTTP client、打开的文件句柄这类运行时对象传进去。Temporal workflow 会回放历史,因此 workflow 代码必须尽量确定性。真正会访问网络、调用模型、写文件的逻辑,都应该放进 activity。
第二步:把不稳定操作放进 activity
activity 是生产可靠性的主要落点。一次模型调用可以是 activity,一次网页搜索可以是 activity,一次 PDF 生成也可以是 activity。每个 activity 都应该设置超时时间和重试策略。这样当网络短暂不可用、API 返回 500、模型调用超时,Temporal 可以只重试失败步骤,而不是让整个智能体从头运行。
这里要特别注意幂等性。Temporal 会在 activity 失败时重试,所以如果 activity 会写外部系统,就要避免重复副作用。比如发送邮件、扣费、创建工单、上传文件,都应该带上稳定的业务 ID,或者先记录外部写入结果。对于纯模型调用,也建议把 workflow id、activity 名称和逻辑步骤写入日志,方便后续排查。
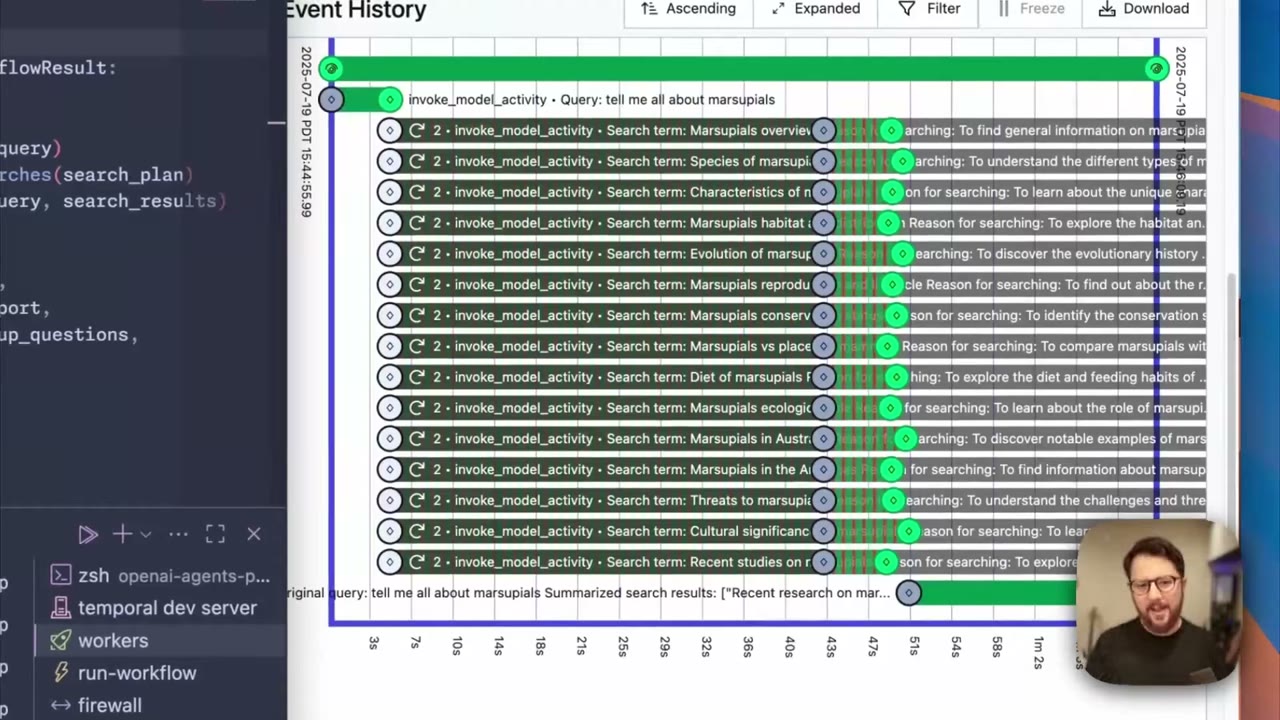
第三步:用事件历史定位问题
Temporal 的事件历史会记录 workflow 的关键变化:activity 被调度、开始执行、失败、重试、超时、收到用户 update、最终完成。这个历史记录相当于一条可靠的调试时间线。以前你可能只能看到一个智能体进程卡住了,现在可以看到到底是哪一步失败、失败了几次、下一次什么时候重试。
Agents SDK 的 tracing 仍然有用。Temporal 告诉你可靠执行层发生了什么,Agents SDK tracing 告诉你模型和工具内部发生了什么。生产排障时,这两个视角最好一起看:Temporal 用来确认任务生命周期,tracing 用来分析模型选择、工具调用和输出质量。
第四步:通过 worker 横向扩容
普通单进程智能体很难扩容,因为所有状态和任务都绑在一个运行时里。Temporal 的 worker 模型更适合长任务。worker 会从任务队列拉取 workflow task 和 activity task。需要更多吞吐时,不必重写智能体逻辑,只要启动更多 worker 即可。它们可以分布在多个容器、多个可用区,甚至不同集群中。
研究类智能体尤其适合这种方式。一个主题可能同时发起多个搜索;另一个任务可能正在等用户回答;第三个任务可能正在生成报告。Temporal 保存工作流状态,worker 只负责执行当前可执行的任务。这样扩容就从改代码变成了增加执行容量。
第五步:用 workflow update 支持人机交互
很多高质量智能体不能立刻开工,因为用户的问题本身可能不够明确。例如用户说想找北美看熊的地点,系统可能还需要知道是野外还是保护区、想看哪种熊、是否需要导游服务。Temporal 的 workflow update 可以让已经启动的 workflow 在运行中接收结构化输入。
一种实用设计是:先由 triage agent 判断是否需要澄清;如果需要,clarification agent 生成问题;workflow 进入等待状态;用户回答后,应用把答案作为 update 发送给 workflow;workflow 收到答案后再继续研究。这样智能体不需要一直占着一个进程等待用户,状态也不会丢。
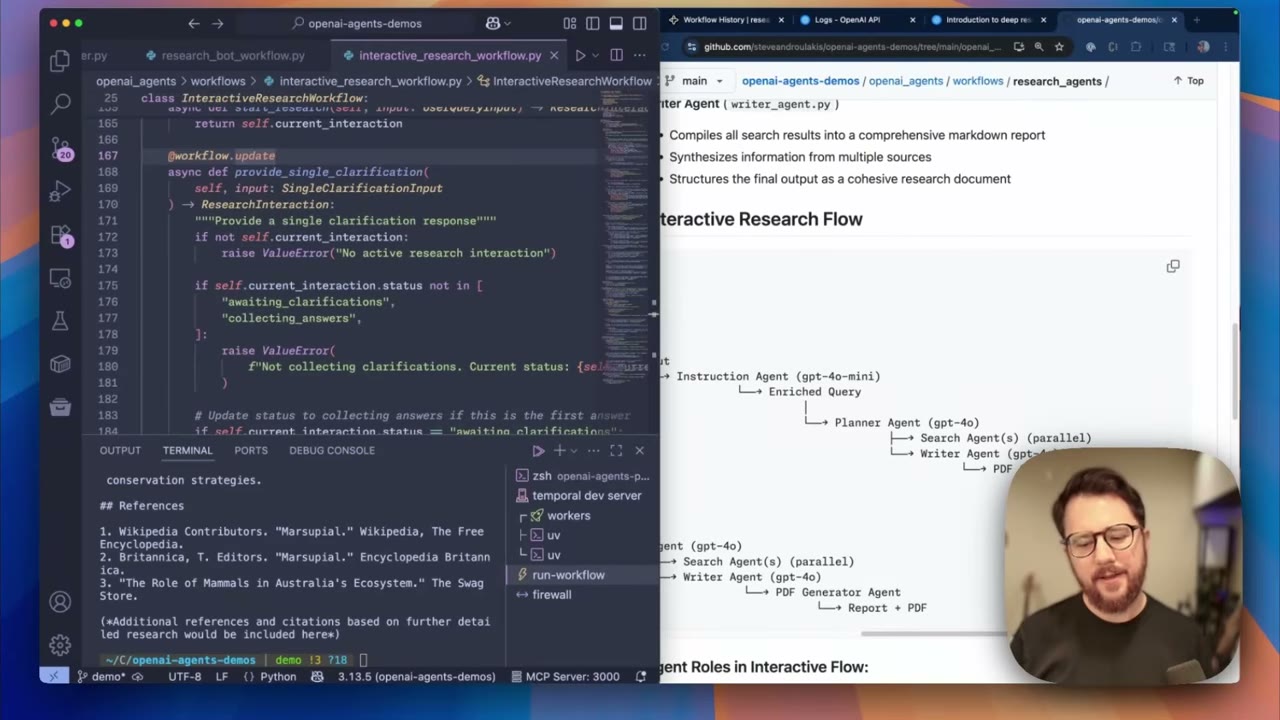
这个模式比一开始强迫用户填完整表单更灵活。agent 可以根据主题动态提出问题,用户可以稍后回答,每次回答都会进入 workflow 历史,方便审计和复盘。
常见错误
第一个错误是在 workflow 代码里直接做网络请求。workflow 需要可回放,外部副作用必须放进 activity。第二个错误是只加重试,却没有考虑幂等性。一个会发邮件或写文件的 activity 如果被重试,可能产生重复结果。第三个错误是把所有工作塞进一个巨大 activity。这样虽然代码简单,但一旦失败,你仍然不知道具体卡在哪一步,也不能只重试最小失败单元。
还有一个容易忽略的问题:不要只把 Temporal 当成崩溃恢复工具。它也是协调层,可以管理长时间等待、人工确认、并行任务、定时器、失败重试和审计历史。对于智能体系统来说,这些能力往往和模型本身一样重要。
上线前检查清单
- workflow 输入是否足够小,并且能序列化。
- workflow 代码是否避免了网络请求、随机数和不可控副作用。
- 模型调用、搜索、爬虫、文件生成是否都放进 activity。
- 每个 activity 是否设置了合理 timeout 和 retry policy。
- 写外部系统的 activity 是否具备幂等设计。
- 是否至少启动多个 worker,验证任务可以被不同 worker 接力执行。
- 是否同时接入 Temporal event history 和 Agents SDK tracing。
- 是否测试过进程崩溃、网络断开、工具代码出错后的恢复路径。
- 是否为需要澄清或审批的任务设计 workflow update。
原视频来源
本文基于 Temporal 的演示视频整理并扩展为独立教程:https://www.youtube.com/watch?v=fFBZqzT4DD8
实操补充:把概念落到项目里
如果你已经理解了文章前面的概念,下一步应该把它落到一个小项目中。建议选择一个边界清楚的任务:例如让智能体读取本地文档并生成迁移清单,或者让 Claude Code 修改一个单独组件并运行测试。先写出输入、输出、工具权限和验收标准,再开始执行。这样可以避免把 SDK、模型能力和业务流程混在一起,导致最后只得到一段看似完整但无法验证的说明。
落地时最重要的是分层。模型层负责理解任务和生成候选方案;工具层负责读取文件、调用 API、写入结果;编排层负责记录状态、重试失败步骤、等待人工确认;验证层负责检查输出是否满足标准。不要让一个提示词承担所有职责。只要任务会跨越多个步骤、多个工具或多个人,就应该把这些职责拆开。
常见落地误区
第一个误区是把示例代码直接搬进生产环境。教程里的代码通常省略权限、日志、幂等和异常恢复,真实项目必须补齐这些部分。第二个误区是只追求模型回答质量,却忽略输入数据质量。没有干净的上下文,再强的模型也只能猜。第三个误区是没有回滚方案。凡是会写数据库、发消息、改文件的动作,都要能追踪、能撤销、能解释。
检查清单
- 是否明确了最终产物,而不是只说“帮我分析”?
- 是否把工具权限限制到当前任务所需的最小集合?
- 是否保留了中间产物,方便发现错误发生在哪一步?
- 是否为失败、超时和人工确认设计了路径?
- 是否有测试、schema 校验、截图或人工审查作为验收?
进一步练习
你可以把同一个任务分别用“纯提示词”“SDK 工具调用”“带编排的工作流”三种方式实现。比较它们的差异:纯提示词最快,但难复用;SDK 工具调用适合中等复杂度;带编排的工作流最重,但最适合长任务和生产环境。这个对比能帮助你判断什么时候该简单处理,什么时候值得引入完整架构。