
为什么 Cursor 3 会改变 AI 编程的组织方式
很多人觉得 AI 编程效率上不去,是因为模型不够强。实际进入多智能体工作流以后,你会发现真正的瓶颈往往不是模型本身,而是工作流结构。只要开始同时运行多个编程智能体,事情就不再是“打开一个聊天框,提一个问题,等结果”这么简单,而是立刻变成了并行任务管理:分支怎么隔离、运行环境怎么同步、云端和本地如何切换、谁在改哪个模块、UI 怎么验收、合并冲突怎么收尾、插件和 MCP 怎么作用到对应项目。
Cursor 3 的价值就在这里。它不是单纯把 AI 放进编辑器,而是把“智能体”提升为一等工作单元。你能更清晰地看到本地会话、云端会话、仓库分组、工作树、浏览器预览和后续审查的关系。再配合 Composer 2 这种更快、成本更低、明显偏向编码任务的模型,原本只敢偶尔用 AI 处理单点工作的开发者,才真正有条件把 AI 纳入日常工程流程。
这篇教程不是视频摘要,也不是功能盘点,而是直接把视频里最有价值的做法提炼成一套可以落地的工作方法:如何搭建 Cursor 3 的多智能体工作流,如何在本地和云端之间分工,如何避免常见配置坑,如何利用插件、MCP、技能包、浏览器预览和设计模式,让多个智能体并行工作时仍然可控、可审、可合并。
从 Agents Window 开始,而不是从一个空聊天框开始
如果你还在沿用旧的使用习惯,一打开 Cursor 就直接开始对着一个会话提需求,那么进入 Cursor 3 以后第一件事应该改掉这个动作。更合理的入口是 agents window,也就是围绕智能体会话组织工作的那个新界面。
这里最关键的认知变化是:每一个 agent session 都应该对应一个明确任务,而不是混着多个目标。一个会话最好只做一件事情,例如:
- 修一个明确的 bug
- 完成一个功能切片
- 做一次局部重构
- 处理一轮 UI 调整
- 跑一次代码评审或浏览器验证
这样做的好处非常直接。等一个智能体返回结果时,你不需要重新回忆“它到底在忙什么”,也不会把多个目标揉在一起导致审查困难。你能快速判断这次改动属于哪个仓库、对应哪一类工作、是在本地跑的还是在云端跑的、下一步该进审查还是继续补充上下文。
在 Cursor 3 里,建议尽快把会话分组方式调整为按仓库分组,而不是按默认 workspace 分组。按仓库分组有三个非常现实的好处:
- 你能一眼看清当前到底有哪些项目在消耗你的注意力
- 你能快速判断哪些 agent 还在运行,哪些已经返回等待处理
- 你能把同一个仓库里的本地任务、云端任务、PR 审查和预览测试自然归到一起
一旦开始并行工作,这种分组会比你想象中重要得多。很多人并不是因为 AI 产出差而效率下降,而是因为他们失去了“工作可见性”。Cursor 3 的新界面本质上是在补这件事。
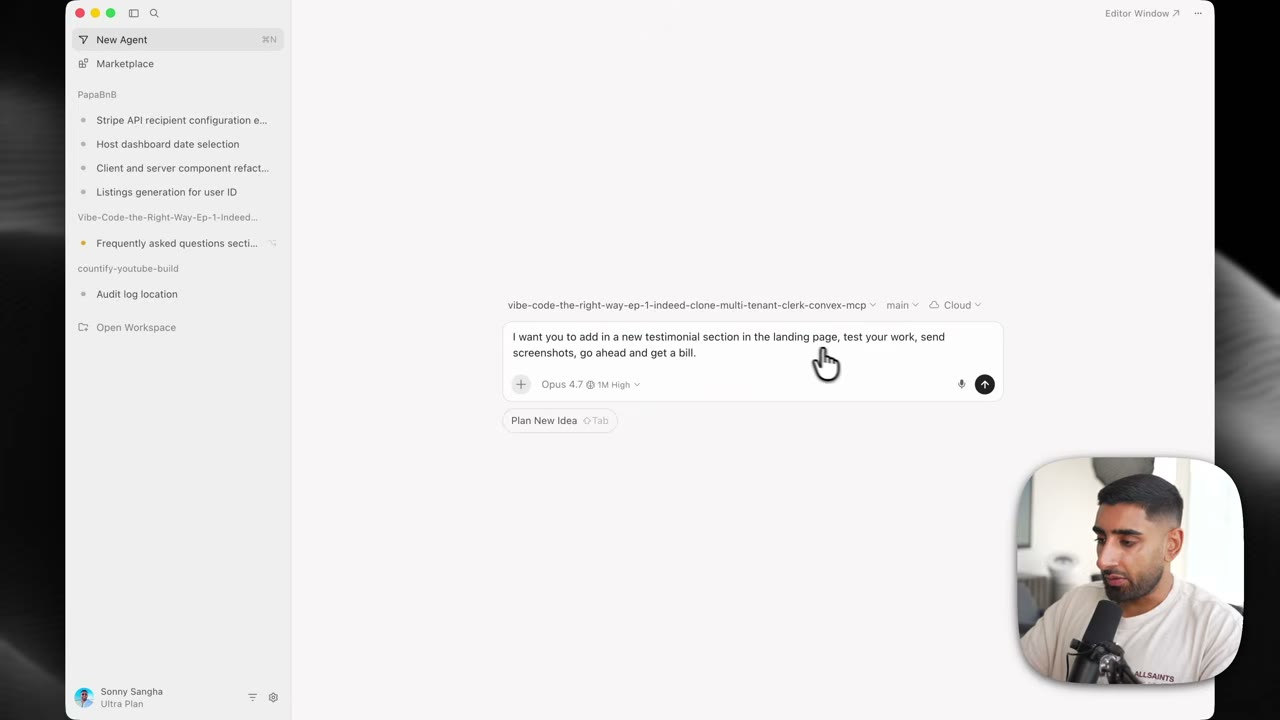
用 Git worktree 给本地智能体建立安全边界
想把本地智能体用稳,最重要的一步不是模型设置,而是文件系统隔离。最推荐的做法是把本地 agent 和 Git worktree 绑定起来使用。
git worktree 的作用,是在同一个 Git 仓库下创建多个独立工作目录,每个目录可以检出到不同分支。对于多智能体开发来说,这几乎是天然适配的能力。因为每个智能体都可以在自己独立的工作树里改代码,不会污染你当前人工开发的主工作目录,也不会和另一个智能体的修改混在一起。
一个稳妥的日常模式通常是这样的:
- 你的主仓库目录保持尽量整洁,用于人工主导的查看、调试和最终收口。
- 每一个比较成型的本地智能体任务,都新建一个 worktree。
- 分支名和目录名都按任务语义命名,不要按模型名命名。
- 本地 agent 只在对应 worktree 中运行。
- 完成后先审查,再决定是否合回主线或转成 PR。
例如,下面是两个示意命令:
# 示例:为 dashboard 调整创建独立 worktree
git worktree add ../app-dashboard-agent -b feat/dashboard-polish
# 示例:为登录态问题创建独立 worktree
git worktree add ../app-auth-fix-agent -b fix/auth-session-timeout
这样命名的价值并不只是“整洁”。当你在 Cursor 的 agents window 里看到多个会话时,目录名、分支名、会话标题三者如果都围绕同一个任务语义展开,你后续在终端、PR、浏览器预览、云端任务面板之间切换时,认知成本会非常低。
为什么 worktree 比 stash 更适合并行智能体开发
有些开发者刚开始会尝试用 git stash 或者直接让多个任务共享一个本地 checkout。这个做法在单人短时实验里可能还能勉强维持,但一旦引入多个智能体,问题会迅速放大:
- 不同任务的文件修改会混杂在一起
- 构建结果和测试结果很难对应到单一任务
- 某些环境问题到底是哪个任务引入的会变得模糊
- 合并冲突会明显增多,因为变更边界不清晰
而 worktree 的优势是天然形成边界。一个 worktree 对应一个任务,就意味着:
- 失败实验可以直接删除,不需要手工拆解污染过的工作区
- 测试结果和任务范围一一对应
- 代码审查更快,因为 diff 不会混入无关变更
- 即使多个智能体并行跑,本地文件状态仍然稳定
给本地智能体下任务时的范围控制
要让 worktree 真正发挥作用,任务描述也必须控制在“一个分支能承载的范围”。不要对本地 agent 说“把这个应用整体优化一下”,这种话听起来高效,实际上最容易产出不可控的大 diff。
更好的任务写法应该是:
- “重构设置页的表单校验逻辑,但不修改 API contract。”
- “为 FAQ 区块补一轮视觉调整,保持现有绿色主题变量体系。”
- “修复登录重定向循环,并补一个最小回归验证。”
- “整理 billing 页面组件结构,但不引入新依赖。”
这种任务粒度更适合本地 agent,也更适合后续审查与合并。
什么时候应该用云端智能体,而不是本地智能体
云端智能体最适合的,不是所有任务,而是那些可以异步推进、并且不值得一直占住你本机注意力的任务。典型场景包括:
- 比较长的功能实现
- 需要后台慢慢跑完的重构
- 浏览器自动化验证
- 草拟 PR
- 预览环境下的 UI 检查
- 你离开工位后还希望继续推进的任务
很多人第一次用云端 agent,会把重点放在“它能不能替代本地”。其实更重要的问题是“它能不能接管适合异步推进的任务”。只要你接受云端是并行执行面而不是本地替代品,你的使用方式会更合理。
一个实用判断标准是:
- 如果任务需要你频繁看终端、反复跑本地服务、临时加日志、快速手工试错,那优先本地。
- 如果任务已经边界清晰,后续主要是等待实现、等待构建、等待测试、等待浏览器执行,那优先云端。
这样分工以后,你可以把高互动密度任务留在本地,把高等待时间任务丢给云端,从而真正形成并行收益。
云端智能体最常见的坑:环境变量和运行前提没有对齐
视频里提到一个特别关键、也特别容易被忽视的问题:云端 agent 在浏览器里尝试截图时,发现缺少环境变量。这个场景很典型,现实中出现概率非常高。
很多开发者会下意识把云端 agent 当作“另一台已经帮你配好的电脑”,其实它更接近“一个需要你声明运行前提的执行环境”。如果你的项目依赖 .env、第三方服务密钥、预览地址、数据库 URL、支付沙箱凭据、认证回调域名等信息,那么这些东西都必须明确配置到云端项目或仓库级设置里。
常见的异常现象包括:
- 本地能跑,云端构建失败
- 云端可以启动页面,但关键区域加载不出来
- 浏览器预览能打开,但截图内容不完整
- 第三方集成静默失败,表面上又不像报错
- 智能体为了继续任务,开始擅自 mock 不该 mock 的逻辑
因此,配置云端 agent 时,至少要逐项确认下面这些内容:
- 项目所需环境变量是否已经在云端设置中定义
- 安装命令和包管理器是否与仓库一致,例如
pnpm、npm或bun - 构建命令、开发命令、预览命令是否准确
- 浏览器测试前是否有 seed 数据或登录前提
- 是否需要指定 Node 版本或系统依赖
一个很有用的提示写法是:
使用当前项目的预览环境。如果缺少 billing 相关环境变量,不要伪造成功结果,直接报告缺失的 key 名称以及受影响的流程。
这种提示的价值是阻止智能体在缺前提的情况下“假装完成”。对于工程工作来说,诚实失败比虚假成功更有价值。
模型选择不要看热度,要看任务经济性
这套工作流里另一个很重要的思想,是不要把所有任务都交给同一个模型。真正可持续的多智能体开发,不是模型越贵越好,而是任务和模型之间的匹配要合理。
从视频信息来看,Composer 2 的吸引力主要在三点:
- 速度快,适合高频日常编码
- 针对编程任务优化,具备较强代码工作能力
- 成本明显更低,适合并行铺开多个 agent
这会直接改变你的行为方式。以前如果每次开一个 agent 都成本不低,你就会把 AI 用在少数“值得”的场景里;一旦模型速度和价格都更适合日常使用,你就会自然开始把更多中等复杂度任务也交给 agent,并行收益才会出现。
一个实用的模型分配策略可以这样建立:
- 高风险、高不确定性、架构敏感或有复杂竞态问题的任务,优先使用你最信赖的强模型。
- 需要更多创意、风格探索、文案方向、UI 方案比较的任务,可以使用更擅长创造性输出的模型。
- 大量日常实现、常规重构、后台并行执行、成本敏感的任务,可以优先交给 Composer 2 这类模型。
关键不在于谁“绝对最好”,而在于你是否把模型当成资源而不是当成信仰。举几个典型判断:
- 一个营销页样式微调,不太值得占用最贵模型。
- 一个登录态偶发 race condition 修复,可能就值得更稳的模型参与。
- 一个范围明确、你本来就会人工审查的大型后台重构,非常适合成本更低的并行模型。
一旦你开始按任务经济性分配模型,多智能体工作流的成本和产出会更平衡。
插件不是“装得越多越好”,而是工作流基础设施
视频里对 Cursor Marketplace 的评价很高,这背后有一个容易被忽略的关键点:Cursor 插件并不只是编辑器小工具。很多插件会连带安装 MCP、skills、commands、hooks,甚至 sub-agents。也就是说,插件可能会直接改变智能体在某个项目里的能力边界。
因此,插件管理不能用“看到有用就装”的心态。更合理的思路是把插件当成项目级基础设施来管理。
什么时候装在项目级,什么时候装在用户级
这是一个非常实际、并且会影响团队一致性的决定。
适合装在项目级的情况:
- 该能力对这个仓库的 agent 表现有直接影响
- 云端 agent 也应该继承这项能力
- 你希望同项目的行为更可复现
- 插件和仓库技术栈强相关,例如认证、支付、特定云服务、设计系统等
适合装在用户级的情况:
- 这是你个人跨项目都想保留的习惯
- 它对不同仓库都通用
- 它更像个人效率增强,而不是项目依赖
一个非常好记的判断标准是:如果一个云端 agent 在这个仓库里缺少该插件会明显做得更差,那么优先项目级安装;如果它只是你个人操作习惯的一部分,则优先用户级安装。
如何判断一个插件值不值得长期保留
不要只看介绍页写得强不强。实际评估时,建议用四个问题筛选:
- 它是否减少了你每周都会重复执行的某个真实步骤?
- 它是否给 agent 增加了稳定、可复用的能力?
- 它会不会引入过多噪音、额外提示或难以理解的自动行为?
- 你能否用一句话说清它在这个项目中的存在理由?
如果第四个问题答不上来,这个插件大概率不该留在项目里。
像视频里提到的偏代码评审增强的插件,就是很典型的“值得长期存在”的类型。因为一旦你让大量 AI 产出 diff,评审就不再是锦上添花,而是质量门槛本身。
MCP 和技能包的真正价值,在于约束智能体行为
很多人把 MCP 或 skills 理解成“给 AI 多接几个工具”。这个理解不算错,但还不够深入。它们真正的价值,在于缩小智能体的模糊空间。
一个通用型 agent 面对跨系统任务时,很容易飘散:一会儿猜命令,一会儿猜目录,一会儿猜项目约定,一会儿自己脑补下一步。你给它配置合适的 MCP 和技能包,本质上是在告诉它:
- 哪些信息源是可信的
- 哪些命令或流程是标准做法
- 哪些能力可以稳定复用
- 哪些工作应该遵守既有约束
在实际项目里,这种约束会带来更高的一致性。常见受益场景包括:
- 与特定代码仓库或 PR 流程强关联的任务
- 需要遵守设计系统规范的前端改动
- 依赖明确文档命令的后端任务
- 需要云端预览和浏览器测试的工作
- 需要固定验收标准的审查类任务
一旦这些能力被项目化,智能体下次接手相似工作时,就不必从零摸索你的工作方式,稳定性会明显提高。
先审查计划,再审查代码
AI 编程里最贵的错误之一,不是写错一行代码,而是方向一开始就错了。Cursor 3 这种 agent-first 界面最值得利用的一点,是你可以更早介入审查:在 diff 生成之前先看计划。
如果一个智能体会先给出计划,不要把这一步当成形式。你应该像看一个简化版工程设计说明那样去检查它:
- 范围是否准确
- 是否定位到了正确文件
- 有没有引入不必要的新技术或新依赖
- 是否假设了它未必具备的运行前提
- 是否区分了实现步骤和验证步骤
计划越模糊,后面的代码就越容易南辕北辙。很多“看起来很忙”的大 diff,本质上只是建立在一个错误方向上。
你可以在提示里直接要求:
开始修改前先给出计划,明确列出目标文件、预期运行命令、验证步骤和所需环境假设。在计划获批前不要开始实现。
这句指令非常值钱。它能显著降低返工率,尤其是在多智能体并行时,因为你不可能盯着每一个智能体边做边纠偏,必须尽量前置风险。
把浏览器预览、截图和视频当成验收证据,而不是装饰
对于 UI 任务,仅仅看代码 diff 远远不够。你真正需要的是“证据”,证明它在渲染层面确实达到了目标,而且没有明显退化。Cursor 3 的浏览器运行和云端预览能力,在这里非常有用。
当一个智能体完成前端改动后,最好不要只接受“已完成样式更新”这种文字结论,而是明确要求它输出:
- 渲染后的截图
- 关键交互路径说明,例如点击了哪里、切换了什么状态
- 如果有缺失环境变量,要明确列出
- 如果涉及响应式布局,要说明移动端和桌面端是否都检查过
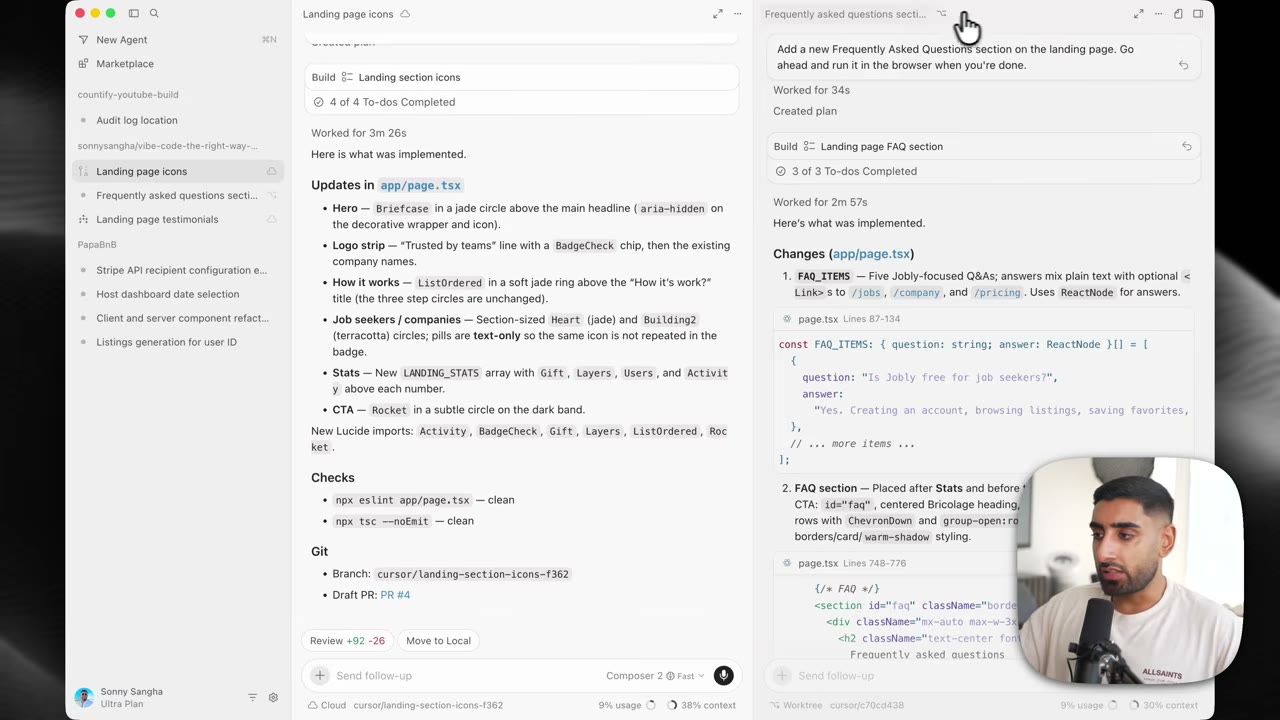
例如,视频里演示 FAQ 区块视觉调整时,一个更好的要求可以是:
在浏览器中运行更新后的页面,验证第一个 FAQ 卡片使用了绿色强调样式,并附上一张渲染状态截图。如果预览依赖缺失环境配置,请明确说明。
这样做的好处是,你不必先把代码拉到本地再自己验证一轮,就可以更快筛掉明显不合格的结果。
但截图不是完整验证
要特别强调一点:截图非常适合做视觉确认,但并不等于完整验收。一个页面看起来正确,不代表它的键盘可达性、网络请求、表单提交、状态同步、权限控制、埋点逻辑也都正确。
因此,比较稳妥的前端验收应该至少叠加几层证据:
- 截图或视频证明它长得对
- 终端构建或测试输出来证明它能跑
- 一段简短说明证明 agent 理解了改动点
- 你自己对 diff 的审查,确认没有引入不该有的副作用
这四层一起用,误判率会低很多。
Design Mode 适合做快速视觉修正,不适合代替工程判断
视频里对 design mode 的演示很有代表性。它的真正价值,不是“让 AI 自动设计”,而是让你在看到具体页面后,可以非常快速地表达视觉修正意见。
比如你打开浏览器预览,马上发现某个 FAQ 卡片应该更突出、某个按钮对比度不够、某个区块留白过大,这些都属于 design mode 很擅长处理的事情。因为它允许你围绕当前渲染结果直接下达短促而明确的修正命令。
适合 design mode 的任务通常包括:
- 层级强调调整
- 间距修正
- 颜色权重调整
- 卡片样式加强
- CTA 突出度增强
- 功能完成后的最后一轮视觉打磨
好的提示例子:
- “把第一个 FAQ 项的背景改成主题里已有的绿色强调色。”
- “减少 hero 区块的上下留白,保持标题对齐不变。”
- “增强次按钮的对比度,但不要新增颜色 token。”
不好的提示例子:
- “把这个页面变好看。”
- “整体重做一下设计。”
- “现代化一点。”
两者差异不在于长度,而在于可执行性。只要你已经知道想测试什么设计决策,design mode 会显著加快视觉迭代;如果你自己都没想清楚,它只会放大模糊。
Multitask Mode 只有在任务边界独立时才真正有用
并行并不天然等于高效率。只有当任务可以被独立审查、独立验证、独立合并时,并行才会带来收益。视频里提到的新 multitask mode 很强,但前提是你要会拆任务。
一个好的拆法可能是:
- 一个智能体只负责 FAQ 样式调整
- 一个智能体只负责移动端间距优化
- 一个智能体只负责文案一致性检查
- 一个智能体只负责浏览器验证并报告问题
这种并行很健康,因为每个输出都能单独判断对错,也不太容易互相覆盖。
不好的拆法则包括:
- 多个智能体同时编辑同一棵组件树
- 多个智能体同时重构同一段状态逻辑
- 没有 worktree 或分支隔离却并行写同一目录
- 没有约定谁的结果最终作为基线
为了降低冲突,建议你在提示中直接声明所有权,例如:
任务 A 只负责 FAQ 样式。
任务 B 只负责移动端 spacing。
任务 C 不改代码,只检查渲染结果并输出问题列表。
这种明确边界的写法,比任何后期冲突解决技巧都更有效。
在本地和云端之间切换,要有明确理由
Cursor 3 很强调本地与云端之间的无缝切换,但“能切换”不代表“应该随便切”。真正高效的做法是有意识地进行工作交接。
几个很实用的切换模式:
- 先在本地查看仓库、确认命令和依赖,再把范围清晰的实现任务移到云端后台继续跑
- 先让云端做广泛探索和初步实现,再把结果拿回本地做最后调试和精修
- 把浏览器测试、预览验证之类高等待时间任务放到云端,同时你在本地处理另一个分支上的高互动任务
好的切换理由包括:
- 你希望任务在后台持续推进
- 你即将离开工位
- 当前任务已经不需要高频人工交互
- 你需要一个更隔离的执行上下文
不好的切换理由包括:
- 任务定义还很模糊
- 运行环境根本没配齐
- 你只是想逃避仔细审查结果
云端不会自动解决模糊问题,它只会让模糊问题跑得更远。
审查、合并、归档和恢复,决定这套系统能否长期运转
一个多智能体工作流好不好用,不只看它能不能“跑起来”,更看它能不能“收得住”。如果收尾纪律差,几天之后整个系统就会变成一堆历史会话、零散分支和说不清来源的改动。
合并前的审查清单
每次准备接收 agent 产出时,至少检查这些事项:
- 回看它最初执行的计划,确认输出没有偏题
- 检查 diff 中是否混入了不相关文件
- 构建结果、测试结果是否和它的结论一致
- 如果改了 UI,是否提供了截图、预览或视频证据
- 有没有遗留调试代码、临时 mock、假数据或敏感信息
- 分支范围是否仍然符合最初任务边界
如果发生合并冲突,可以利用工具提供的快速解决能力,但千万不要把“冲突已消除”误等同于“语义正确”。无论是自动化冲突解决还是一键推送,最终都要回到代码语义本身来确认。
归档是工作流卫生,不是可有可无
视频里提到会话归档与撤销归档,这一点也非常实用。对于并行 agent 工作流来说,界面里只保留“当前还需要注意的东西”非常重要。否则随着会话数量增多,你会失去对真实待办的感知。
建议形成一个简单习惯:
- 已经合并或明确放弃的会话及时归档
- 仍需跟进的问题保留在当前视图
- 如果误归档,优先用可恢复机制,而不是重新创建上下文
这样 agents window 才会真正像操作面板,而不是聊天记录堆积区。
一套适合日常使用的 Cursor 3 操作模型
如果你希望把前面的原则收敛成一套每天都能执行的流程,可以按下面这个顺序来:
- 打开 agents window,并切到按仓库分组。
- 识别今天最值得并行推进的 2 到 4 个任务。
- 为每个实质性任务建立独立 worktree 或独立云端任务。
- 按风险、复杂度和成本给每个任务分配合适模型。
- 确认项目级插件、MCP、技能包是否已具备。
- 要求智能体先给计划,再批准实施。
- 在后台 agent 运行时,你自己处理一个最需要高杠杆人工判断的任务。
- 结果返回后,查看 diff、截图、构建、测试与浏览器预览。
- 只合并边界清晰、验证充分的工作。
- 归档已完成会话,并记录需要后续衔接的事项。
当你形成这种节奏以后,Cursor 3 就不再只是“更好的 AI 编辑器”,而会变成一套并行软件执行的调度界面。
几个最容易让多智能体工作流变糟的错误
错误一:没有分支隔离就让多个智能体同时写代码
这是最常见、也最伤的错误。看似节省准备时间,实际上会在后期审查和冲突解决中成倍偿还。
错误二:所有任务都用同一个模型
这通常意味着你要么浪费预算,要么浪费时间。模型应该服从任务性质,而不是反过来。
错误三:插件只看“能不能装”,不看“装在哪”
如果一个能力应该作用到云端项目,却只装在用户级,效果会不完整;如果只是你个人偏好却装到项目级,也可能给团队增加噪音。
错误四:把截图当成完整验证
页面看着对,并不代表逻辑、交互、可访问性、状态同步都没问题。
错误五:计划审查流于形式
计划模糊,结果大概率也模糊。越晚发现方向错,返工越贵。
错误六:忽视云端环境一致性
缺失环境变量、Node 版本不一致、预览命令错误,这些都足以让一个看似“能力很强”的云端 agent 输出不可信结果。
最终操作清单
在你真正依赖 Cursor 3 跑多智能体项目之前,建议对照下面这份清单逐项确认:
- 你已经把 Cursor 3 的 agents window 作为主要入口,而不是仅靠单一聊天框。
- 会话已经按仓库分组,能够快速区分项目边界。
- 每个智能体只承担一个清晰任务,不在同一会话里混多个目标。
- 本地智能体运行在独立 Git worktree 中。
- 云端智能体所需环境变量和运行前提已经配置齐全。
- 模型分配基于任务风险、复杂度、速度和成本,而不是盲目统一。
- 插件已按项目级或用户级正确安装。
- 适合标准化的任务已经接入 MCP 或技能包,以提高可重复性。
- 智能体在实施前会先给出计划,并经过审查。
- 涉及前端改动时,会要求浏览器预览、截图或视频作为证据。
- 合并前会同时检查 diff、构建输出、测试结果和可视化证据。
- 完成的会话会及时归档,保持当前队列干净可读。
如果这份清单大部分都能做到,那么 Cursor 3 带来的就不只是“写代码更快”,而是让你真正具备管理多条 AI 执行链路的能力。那时,AI 编程的单位就不再是一个聊天窗口,而是一组可以被分配、监督、验证和合并的智能体任务。
来源说明
本文基于 Sonny Sangha 发布于 2026 年 5 月 13 日的 YouTube 教程视频《Cursor 3.0 is officially the new King (My AI coding setup revealed)》整理与重构,原始链接:https://www.youtube.com/watch?v=la_tAgBKqO0