Model Context Protocol,通常缩写为 MCP,正在迅速成为 AI 应用连接外部系统的一种标准方式。很多人第一次接触它时,会把注意力放在“协议”两个字上,结果越看越抽象。其实只要换一个角度理解,MCP 的核心非常务实:让模型驱动的应用用统一的方法读取外部信息、调用外部能力、执行真实动作。这正是很多 AI 产品从“会聊天”走向“能办事”时必须补上的那一层。
这篇教程不做视频摘要,也不做概念速记,而是直接把你带到可落地的层面:为什么 MCP 会出现、它解决了什么实际问题、服务端和客户端各自负责什么、为什么资源(resources)、工具(tools)、提示模板(prompts)是构建时最先要理解的三类能力,以及怎样用一个最小的 Python 项目把自己的第一个 MCP Server 和 MCP Client 搭起来。读完后,你应该能独立判断:某个需求是不是适合用 MCP 来做,应该把某种能力设计成 resource 还是 tool,本地调试该用标准输入输出还是 HTTP,远程部署时有哪些安全边界必须提前考虑。
为什么单靠大模型还不够
先把一个常见误解拆开。很多人以为“模型足够强”之后,AI 自然就能帮你查询系统、操作网站、预订服务、调用企业内部工具。现实不是这样。
一个普通 LLM 最基础的工作模式是这样的:
- 用户发送一段输入。
- 模型生成文本、图像、音频或其他支持的输出。
这适合回答问题、写文案、解释概念、翻译内容,但一旦任务变成“去做一件真实的事”,问题就来了。
比如做一个航班预订助手,用户说:“帮我找下周二从伦敦飞迪拜的便宜航班,比较一下价格和舒适度,再替我订掉。”这时模型本身并不能直接:
- 登录第三方航司或聚合平台;
- 读取实时票价;
- 对比多家返回结果;
- 记住用户过往偏好;
- 在拿到足够信息后继续推进流程;
- 最后真正执行预订动作。
它能做的是“根据已有上下文生成一段看起来合理的话”。但“真实系统动作”不是语言生成的自然延伸,而是要通过外部能力来完成。
这就是 AI Agent 出场的位置。Agent 不等于模型本身,它更像是一个有控制循环的执行层:接收用户目标、决定下一步做什么、何时读取外部数据、何时调用外部工具、何时继续迭代、何时结束任务。过去我们用脚本、自动化编排器、工作流系统来做这类事情;现在 AI Agent 只是把“决策环节”部分交给了模型。
而 MCP 的价值就在于:它给 Agent 和外部能力之间提供了一套统一的接口约定。你不必针对每个 AI 应用都写一套专用集成,也不必让每个模型客户端都直接理解各家五花八门的 API。只要服务端按 MCP 规范暴露能力,客户端按 MCP 规范消费能力,二者就能对接。
用一句人话理解 MCP
把 Model Context Protocol 拆开看会很清楚:
- Model:模型,或者说由模型驱动的应用。
- Context:模型完成任务所需的外部上下文与外部能力。
- Protocol:通信与交互的标准规则。
所以 MCP 不是“新的模型”,也不是“新的 Agent 框架”,而是一套标准化约定:让 AI 应用用一致的方式获取上下文、发现能力、调用能力。
这一点特别关键。很多团队在做 AI 工具接入时,最痛苦的不是模型提示词,而是接口碎片化:
- 这家需要 HTTP;
- 那家走本地进程;
- 这边返回 JSON 结构混乱;
- 那边把错误混在自然语言里;
- 不同工具的命名、参数、身份认证、状态处理方式都不一样。
MCP 试图解决的正是这种集成层面的混乱。它不保证你的业务逻辑就一定优雅,也不替你完成权限设计,但它提供了一条共同的轨道。对工程团队来说,这比“某个 demo 看起来能跑”重要得多。
先建立正确的架构脑图
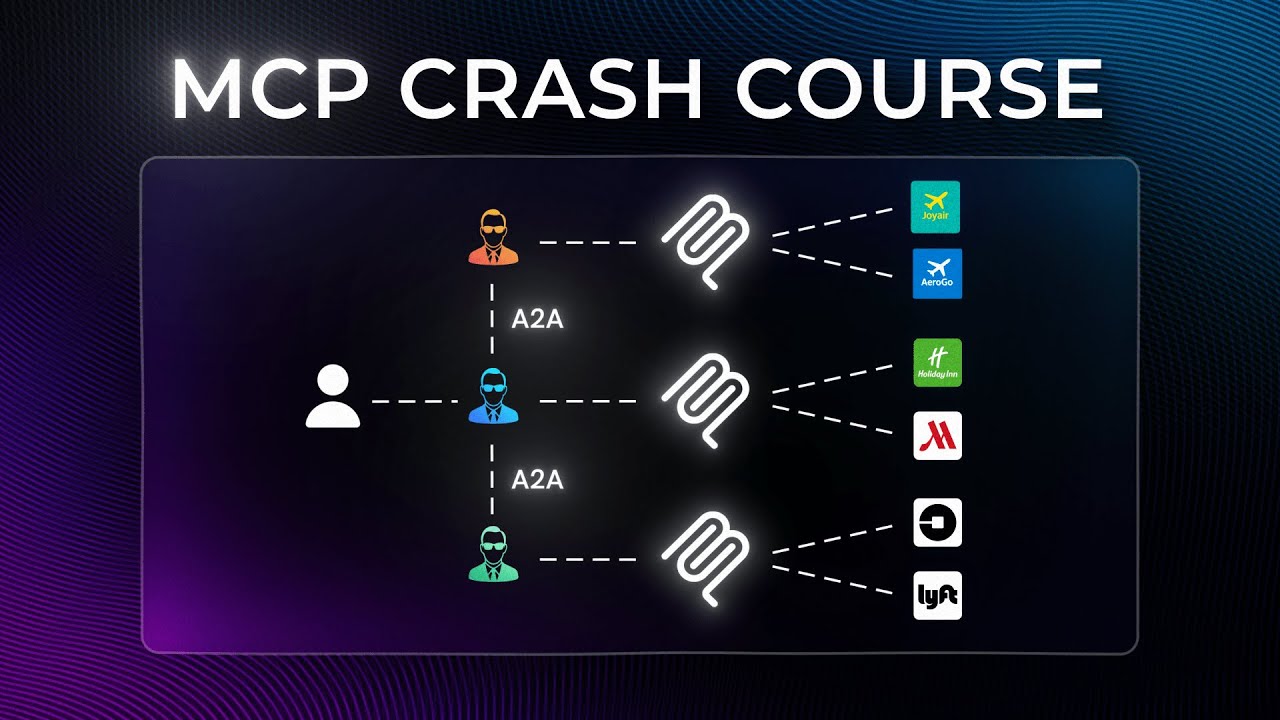
很多初学者一上来就记术语,结果只记住了“server”“client”“tool”,却不知道它们在系统里各自扮演什么角色。先建立一个简单架构脑图。
在一个典型 MCP 系统里,至少有三层:
- 用户实际使用的宿主应用,比如 IDE 助手、聊天应用、自定义 Python 程序、Agent 运行时。
- 宿主应用内部的 MCP Client,负责按协议与外部 MCP Server 通信。
- 一个或多个 MCP Server,对外暴露资源、工具、提示模板等能力,并把这些能力翻译成真实的系统行为。
也就是说,客户端不是业务实现层,服务端才是对接外部系统的能力层。
把职责划清后,很多设计问题就容易判断了:
- 哪些东西应该留在服务端?外部系统集成、工具实现、受控数据读取。
- 哪些东西应该由客户端负责?连接、能力发现、会话协调、结果展示或进一步编排。
- 哪些东西属于模型或 Agent 逻辑?任务分解、何时调用什么能力、如何基于返回内容推进下一步。
如果你把这些边界混在一起,后面一定会出现难以调试的问题。例如:工具到底是没注册成功,还是客户端没发现,还是模型根本没选中它?结构清晰时,这些问题是可以逐层定位的。
资源、工具、提示模板:最先要吃透的三类能力
MCP 规范里可以继续深挖很多细节,但第一次上手时,最需要理解的是三个最常见也最实用的概念:resources、tools、prompts。
1. Resource:给模型看的“可读取上下文”
Resource 适合暴露那些以“读取”为主、不会产生副作用的信息。它更像是模型可按需获取的上下文来源。
典型例子包括:
- 机场列表;
- 产品目录;
- 公司制度文档;
- 知识库片段;
- 静态配置;
- 某类对象的参考数据。
在航班例子中,机场列表非常适合作为 resource,因为客户端或 Agent 可能需要先读取可信的机场参考数据,再决定如何构造后续查询。
Resource 设计时最容易犯的错是“看似结构化,实际上很脏”。比如把机场编码、城市说明、注释、错误格式、额外描述混在一起。模型不是不能猜,但你不应该把可明确结构化的数据留给模型去猜。Resource 越稳定、越清晰,后续工具调用质量越高。
2. Tool:真正执行动作或查询逻辑的能力
Tool 是大多数人最关心的部分,因为它代表“能做事”。
典型例子包括:
- 搜索航班;
- 创建预订;
- 查询数据库;
- 创建工单;
- 调用企业内部审批接口;
- 读取需要参数的动态查询结果;
- 对某个对象执行变更。
你可以把 tool 理解为“有输入参数、有执行逻辑、有结构化结果”的操作接口。和普通函数不同,MCP Tool 的设计对象不是单纯的人类开发者,而是“客户端 + 模型 + 后续自动化流程”三方共同消费,因此命名、参数约束、返回结构都要更克制、更清晰。
3. Prompt:可复用的交互指令模板
Prompt 在这里不是泛泛而谈的“提示词工程”,而是服务端对外提供的一种可复用模板能力。它的价值在于把一些容易重复出现的交互流程固定下来。
例如:
- 预订前应收集哪些缺失字段;
- 比较多个航班结果时应按哪些标准排序;
- 执行写操作前是否要求再次确认;
- 当用户信息不完整时如何向用户追问。
Prompt 不是补锅工具。它不能掩盖糟糕的 tool 设计。但在流程一致性上非常有帮助,尤其适合让不同客户端、不同宿主应用在调用同一个 MCP Server 时维持相近的交互质量。
JSON-RPC 2.0 为什么值得你认真看待
教程里特别提到 MCP 通信基于 JSON-RPC 2.0。这绝不是一个可忽略的小细节,因为它直接决定了客户端与服务端之间的消息组织方式。
与其把每次通信都做成自由发挥的 JSON,不如通过 JSON-RPC 使用统一的结构:
- method 表示要调用什么方法;
- params 表示参数;
- id 用来关联请求和响应;
- 出错时也有统一错误结构。
这件事在只有一个 demo 时似乎不明显,但当你的客户端需要接多个 MCP Server、或者你的服务端要给多个宿主应用使用时,统一协议带来的收益会非常大。你不用为每个集成对象重新设计一套请求信封,也更容易做日志、诊断、复用和调试。
另一个容易被忽视的点是:连接通常是有状态的。不要想当然地把它理解成每次请求都是完全独立的“无记忆 HTTP 调用”。不同 SDK、不同传输方式下,状态管理和会话行为会影响调试与运行结果。尤其是当客户端需要先发现能力、再持续调用时,会话存在感会比普通 REST API 更强。
本地运行还是远程托管:先选对传输模式
MCP Server 常见有两种运行方式:本地和远程。
本地运行:最适合入门和调试
本地模式通常是由宿主应用直接拉起一个 MCP Server 进程,然后通过标准输入输出(stdio)进行通信。对初学者来说,这是最容易起步的方式,因为:
- 不需要先搞 HTTP 服务、反向代理、域名和鉴权;
- 调试链路更短;
- 本机开发时延迟更低;
- 适合实验性项目和单人环境。
如果你是在 IDE、代码助手或本地 Agent 工具中接入 MCP,很多时候最先接触到的就是这种模式。
远程托管:适合共享、内网和统一治理
远程模式则是把 MCP Server 部署到组织内部或供应商侧,再由客户端通过 HTTP 连接。它适用于:
- 多个用户或多个应用要共享同一个能力入口;
- 服务端必须靠近受保护系统;
- 凭证不希望散落在每台本地机器上;
- 需要统一监控、审计、版本管理和访问控制。
但远程模式也带来更现实的问题:
- 身份认证怎么做;
- 谁能调用哪些工具;
- 传给远程服务端的提示与业务数据是否包含敏感信息;
- 服务端日志保留什么;
- 写操作是否具备幂等保护或审计追踪;
- 网络抖动和超时如何处理。
换句话说,本地模式关注“怎么快速跑起来”,远程模式关注“怎么可靠地被别人长期使用”。
在写自己的服务端之前,先会“接入别人写好的服务端”
很多入门者在理解 MCP 时只盯着服务端代码,结果忽略了一个事实:现实中大量场景是“你先作为客户端使用现成的 MCP Server”。这一步理解透了,后面自己做服务端时才知道别人为什么会抱怨你的设计不好用。
常见做法是:在支持 MCP 的 IDE、Agent 工具或桌面应用里配置一个 MCP 服务器条目。
如果是本地服务器,配置通常包括:
- 启动命令;
- 启动参数;
- 必要的环境变量。
如果是远程服务器,配置通常变成:
- 服务器 URL;
- 认证信息;
- 某些情况下的额外请求头或连接选项。
这时你可以记住一个非常实用的判断法:
- 客户端负责拉起进程时,重点是 command + args。
- 客户端连接已存在的服务时,重点是 URL + auth。

初学者最容易误判的一点是:以为“只要连上了,模型就自然会用好这些能力”。实际上要得到稳定结果,需要三层都靠谱:
- 服务端暴露的能力清晰、命名合理、返回结构稳定;
- 客户端能正确发现并调用这些能力;
- 模型或宿主应用有足够明确的指引去选择合适的能力。
任何一层做差,都会让整个系统表现得像“有时会,有时不会”。
搭建你的第一个 Python MCP 项目
第一次实践时,不要把目标设成“做一个完整可生产的 Agent 平台”。更稳妥的方式是做一个极简项目,例如一个“航班预订 MCP 服务端”:
- 一个 resource:
airports,提供机场参考数据; - 一个查询类 tool:
search_flights; - 一个写入类 tool:
create_booking; - 一个或两个 prompts,用于指导收集信息与执行预订。
教程材料里使用了 uv 初始化 Python 项目并安装 MCP 相关依赖。一个代表性的流程如下:
# 示例命令
uv init flight-booking-server
cd flight-booking-server
uv add mcp
这里要注意两个工程判断:
第一,这类命令更适合视为“代表性的初始化流程”,不要死背字面。不同版本 SDK、不同实验环境下,命令细节可能变化。你应该抓住的是先建立干净项目,再显式加入 MCP SDK这个动作,而不是某个具体命令文本。
第二,第一次学习时不要把 MCP 直接塞进一个庞大的既有代码库。那会让你无法分辨问题是来自协议集成、依赖版本、业务逻辑,还是老项目本身。最小项目结构越干净,学习效率越高。
一个非常适合练手的目录结构可以只有:
flight-booking-server/
├── pyproject.toml
├── server.py
├── client.py
└── data/
其中 data/ 可以放机场静态数据,方便你把“参考数据”和“执行逻辑”区分开。
在写装饰器之前,先设计能力边界
很多教程演示会直接写 @resource、@tool、@prompt。实际工程里,最好先做一步设计:先写出你打算暴露的能力清单,以及每个能力的输入输出边界。
以航班项目为例,先明确:
airports:返回稳定的机场参考数据,不承担搜索逻辑。search_flights(origin, destination, date, preference):根据参数返回标准化的候选航班列表。create_booking(flight_id, passenger_name, email):执行预订,返回预订确认对象或结构化错误。booking_prompt:描述执行预订前如何收集缺失字段、何时要求确认。
这一步看似慢,实际上能避免一个大坑:直接把后端原始函数“硬套”成 MCP 能力。那样通常能跑,但不好用。客户端和模型最怕的是能力表面看起来很多,实际每个都边界模糊、命名随意、输入输出不稳。
好用的 MCP 服务端,能力表面应该尽可能“无惊喜”。别人看到名字就知道它大概做什么,看到参数就知道怎么调用,看到返回结果就知道下一步如何处理。
服务端实现:先从 Resource 开始
在教程演示里,Python 侧会先初始化一个 MCP Server 对象,然后为不同函数加上对应装饰器。不同 SDK 版本的 import 可能略有变化,但整体模式大致一致。
例如会先有这样一个初始化概念:
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("flight-booking")
第一步:给机场数据加上 Resource
机场列表是典型的 resource,因为它主要提供只读上下文,而不是执行动作。一个概念性写法会类似这样:
@mcp.resource("file://airports")
def get_airports() -> str:
return "LHR, London Heathrow\nDXB, Dubai\nSIN, Singapore"
这里最值得关注的不是字面语法,而是三个设计点:
- 资源标识要清楚,客户端容易发现;
- 返回内容要稳定、可读、尽量结构化;
- 资源适合承载被多次读取的参考上下文。
如果你把机场数据写得过于随意,例如混入长篇说明、注释、非标准字段、甚至错误格式,那么后续模型在调用航班搜索工具时就必须额外猜测和纠错。资源不是“能返回点东西就行”,而是后续推理质量的地基。
再加入 Tool:把真正能办事的能力暴露出来
接下来是查询与预订两个核心工具。一个概念化示例可以类似这样:
@mcp.tool()
def search_flights(origin: str, destination: str, date: str, preference: str = "balanced"):
return {
"results": [
{
"flight_id": "FL-101",
"airline": "Demo Air",
"price": 480,
"duration": "7h 40m",
"cabin": "economy"
}
]
}
@mcp.tool()
def create_booking(flight_id: str, passenger_name: str, email: str):
return {
"booking_id": "BK-9001",
"flight_id": flight_id,
"status": "confirmed",
"passenger_name": passenger_name,
"email": email,
}
这里有几个非常实际的工程决策。
决策一:输入参数要显式
不要让工具去猜用户到底传了什么。像 origin、destination、date、preference 这种字段就应该明确列出。如果某些字段可选,也要能从函数签名或 schema 上看出来。输入边界越清晰,客户端越容易调用,模型越不容易误用。
决策二:输出尽量结构化
很多人第一次做 tool 时喜欢返回一大段自然语言,例如“预订成功啦,你的航班已锁定”。这对终端用户看起来很友好,但对系统编排不友好。更稳妥的做法是返回结构化对象,例如:
booking_idstatusflight_idpassenger_nameemail
这样宿主应用可以自由决定:是直接展示,还是写入日志,还是交给后续流程继续处理。自然语言描述应该由客户端或模型负责生成,而不是让 tool 输出替代结构化数据。
决策三:区分“查”和“改”
search_flights 是查,create_booking 是改。前者即使重复调用问题也不大,后者则具备副作用,必须更谨慎。这种差异应该反映在你的交互设计中,例如:
- 对写操作增加确认环节;
- 缺失必填字段时不应“尽量猜”后执行;
- 返回结果里保留可审计标识;
- 若未来接入真实系统,还要考虑幂等保护与重放风险。
Prompt 的正确用法:让流程一致,而不是掩盖设计问题
Prompt 适合封装一些重复出现的交互规范。例如:当用户想订票时,应先确认出发地、目的地、日期、预算偏好和乘客信息,再决定是否调用 create_booking。一个概念化示意可类似:
@mcp.prompt()
def booking_prompt() -> str:
return (
"When the user asks to book a flight, confirm origin, destination, date, "
"budget preference, and passenger details before calling create_booking."
)
它的价值不在于“让模型更聪明”,而在于让不同客户端在同一类场景下采用一致的操作纪律。如果没有这样的提示模板,某个客户端可能在用户信息不全时直接执行写操作,另一个客户端则会先追问确认,行为差异会非常大。
但要警惕一点:Prompt 不能修复差劲的 Tool。参数不清、命名模糊、返回混乱,这些根本问题不是靠多写几句提示词就能补回来的。
客户端怎么写:先发现能力,再调用能力
有了服务端,客户端的职责就容易理解了。它至少要做四件事:
- 连接到 MCP Server;
- 发现服务端提供了哪些能力;
- 读取 resource 或调用 tool;
- 把结果展示给用户,或者送回 Agent 循环继续决策。
如果你是在自己的 Python 应用中接入,SDK 往往会帮你处理底层 transport 细节。你更关心的是会话建立与能力调用顺序。一个概念化流程大致可以表示成:
# 仅示意的伪代码
client = connect_to_mcp_server(...)
capabilities = client.list_capabilities()
airports = client.read_resource("file://airports")
flights = client.call_tool("search_flights", {
"origin": "LHR",
"destination": "DXB",
"date": "2026-06-01",
"preference": "cheap"
})
这里最重要的习惯是:尽量先发现能力,不要到处硬编码假设。
为什么?因为一旦出现问题,你能很快判断:
- 服务端根本没把这个 tool 注册出来;
- 客户端配置没连对;
- 还是模型只是没选中它。
调试时,能力发现是第一道检查线。如果客户端连 airports 都列不出来,就没必要先怀疑模型推理。
配置现成 MCP Server 时最容易踩的坑
哪怕你先不自己写服务端,只是接入现成服务端,也有一些高频配置陷阱。
1. 把本地模式和远程模式配置思路混用
本地模式通常需要:
- 启动命令;
- 参数;
- 环境变量。
远程模式通常需要:
- URL;
- 认证;
- 有时还包括额外请求头。
你不能把“本地启动命令的思维”套在远程地址上,也不能把“远程 URL 的思维”套在本地进程模式上。先分清 transport 再谈配置。
2. 只验证“连上了”,不验证“能发现能力”
看到客户端面板里没有报错,不代表它真的能使用服务端。正确的验证方式是:
- 能否列出 resources;
- 能否列出 tools;
- 能否读取某个简单 resource;
- 能否成功调用一个无副作用的 tool。
3. 让敏感数据在远程服务器上裸奔
当服务端由第三方托管时,你必须额外审视:
- 提示词中有没有客户隐私;
- 工具调用是否包含企业内部标识;
- 响应数据是否会被记录;
- 认证 token 如何保存与轮换。
如果这些问题没有答案,先别急着把远程 MCP 接入到真实业务链路里。
一个完整的端到端思路示例
现在把这些概念串起来,看看一个合理的流程应该怎么工作。
假设用户说:“帮我找一张下周二从伦敦到迪拜的便宜机票,用 Priya Nair 的名字订。”
一个设计良好的 MCP 系统,可以按下面顺序执行:
- 客户端接收用户请求。
- 根据 prompt 或内置流程检查是否缺少必要信息,例如邮箱、确切日期格式、预算偏好。
- 如有必要,先读取
airports资源,把地点标准化成可用机场编码或参考项。 - 调用
search_flights,传入结构化参数。 - 基于返回结果按“便宜优先”进行筛选或排序。
- 如果还缺用户确认,则先确认;如果规则允许自动选择,则选中目标航班。
- 在所有必需字段齐全后,调用
create_booking。 - 把
booking_id、航班信息和状态回给用户。
这才是真正的“模型借助外部能力完成任务”。模型不是在假装知道航班结果,也不是把一堆外部 API 拼成一坨不透明逻辑,而是在标准协议上协调能力、推进流程。
你应该如何验证自己的第一个实现
判断“我的第一个 MCP 项目是不是已经跑通”,不要只看一条 happy path。至少检查以下项目:
- 服务端能否稳定启动;
- 客户端能否发现
airportsresource; - 客户端能否发现
search_flights与create_booking两个 tool; - resource 读取结果是否格式清晰、可复用;
search_flights返回值是否是稳定的结构化列表;create_booking在缺字段时是否明确失败,而不是含糊其辞;- 成功预订时是否返回固定字段,例如
booking_id与status; - 非法输入时是否产生显式错误,便于客户端处理。
如果你使用了实验环境或教学 lab,尽量把 lab 中的每个小任务都视为能力校验点,而不是“答题步骤”。例如:
- 初始化项目是否成功;
- MCP 依赖是否安装到正确环境;
- resource decorator 是否加在正确函数上;
- tool decorator 是否作用于真正有参数和业务意义的函数;
- prompt 是否明确了流程要求。
这种逐项验证的习惯,比单纯“能跑出一次结果”更重要。因为你未来做的不是演示,而是要维护、扩展、让别人接入的系统。
真实项目里最重要的几个设计原则
能力命名要表达业务意图
search_flights、create_booking 这种名字,一眼就知道它干什么。相反,像 process、execute、runTask 这类模糊名称,短期省事,长期非常难维护。MCP 的消费者并不只有写服务端的人,还包括客户端开发者、模型决策层、未来维护者。
Tool 参数越少越好,但不能少到模糊
好的参数设计不是“把一切都塞进去”,也不是“让模型自己猜”。应该是只暴露真正必要的信息,同时保持语义清晰。比如航班搜索需要出发地、目的地、日期、偏好;但未必要把几十个后端内部参数全暴露出来。
返回结构要稳定
你今天返回 price,明天改成 ticket_price,后天又把时长放进一句自然语言里,这会让客户端和上层流程快速失控。MCP 是协议层能力,不应该频繁做随意的输出格式漂移。
把“写操作”当成高风险能力对待
只读 resource 和查询型 tool 风险较低;任何会创建、修改、删除真实状态的 tool 都应该更保守。预订、下单、发消息、改库存这类能力,必须配合确认、权限、日志、失败回滚或最少也要有审计标识。
先让能力边界清楚,再谈复杂 Agent 编排
很多人一上来就想接大型框架、做多轮自主决策、做复杂推理链。其实如果 resource、tool、prompt 三类基础能力都还没设计清楚,再复杂的 Agent 也只是把混乱放大。正确顺序应该是:
- 先把能力接口做清楚;
- 再把客户端发现与调用流程跑通;
- 最后才去扩展复杂 Agent 行为。
最终操作检查清单
在你把第一个 MCP 服务端或客户端交给别人使用之前,至少逐项确认以下内容:
- 已明确哪些能力属于 resource,哪些属于 tool,哪些属于 prompt。
- 每个 tool 的参数都有清晰语义,且没有依赖隐式猜测。
- tool 返回值采用稳定的结构化对象,而不是只返回自然语言。
- 本地调试优先使用 stdio;需要共享访问时再切换到 HTTP。
- 客户端已验证 capability discovery,不是只验证“没有报错”。
- 对写操作加入确认策略,不在信息缺失时盲目执行。
- 如果连接远程服务端,已评估认证、日志、隐私、权限与信任边界。
- capability 名称体现业务意图,避免模糊抽象命名。
- 已测试正常路径、缺字段路径、非法输入路径和失败返回路径。
- 客户端连接说明完整:本地模式写清 command + args,远程模式写清 URL + auth。
- 如果某条命令只是示意,文档中已标明“示例命令”,避免读者直接照抄后因版本差异踩坑。
- 如果 resource 提供参考数据,内容已尽量保持整洁、一致、可预测。
结语:把 MCP 当成“能力边界标准”而不是“又一个 AI 热词”
MCP 真正重要的地方,不是它给 AI 工程又增加了一个新缩写,而是它把“模型应用”和“真实世界能力”之间的边界标准化了。边界一旦标准化,客户端可以复用,服务端可以替换,能力可以被多个宿主消费,调试也能按层次展开。这就是它在工程上的价值。
如果你现在要开始自己的第一个实践,不需要一上来就搞一个庞大的 Agent 平台。最好的起点反而很小:
- 一个 resource;
- 两个 tool;
- 一个 prompt;
- 一个最小客户端;
- 一条清楚的本地调试链路。
先把这些东西做得边界明确、返回稳定、调用路径可验证。等你真正理解了“协议、能力、客户端、服务端、状态、信任边界”这些概念之后,再去扩展远程部署、共享接入、复杂工作流和更强的 Agent 编排,速度会快很多,返工也会少很多。
来源说明:本文基于 KodeKloud 发布的教程视频 “MCP Tutorial: Build Your First MCP Server and Client from Scratch (Free Labs)” 整理与重构写成。原始链接:https://www.youtube.com/watch?v=RhTiAOGwbYE